
Sistema Operativo: come funziona e codice di Linux
In questo articolo si vedrà il funzionamento di un sistema operativo analizzando in particolare il codice di Linux.
Di seguito, un menù di tutti gli argomenti trattati:
- Programmazione di Sistema e Concorrente
- Kernel Linux
- Gestione della Memoria
- Input Output a livello Hardware
WEBSITE HOME PAGE → edoardosorgentone.it (click here)
Cito qui il manuale “Programmazione e Struttura del sistema operativo Linux-Appunti del corso di Architettura dei Calcolatori e Sistemi Operativi (AXO)” di Giuseppe Pelagatti, da cui prendo spunto per la nostra discussione.
INTRODUZIONE
Uno dei concetti basici dei sistemi operativi è il concetto di processo.Una delle funzioni più importanti in assoluto del SO è proprio quella di gestire i processi.
Siamo generalmente abituati all’esecuzione sequenziale di un programma, ma in base a quanto detto sin ora un calcolatore deve essere in grado di eseguire N programmi alla volta.Questo tipo di esecuzione è comoda per il programmatore(perchè egli sa che non ci saranno interferenze con altri programmi) ma non adatta all’esecuzione contemporanea di più programmi.
Sostanzialmente si vuole che l’esecuzione avvenga senza attendere che altri programmi siano già terminati(parallelismo) e assicurarsi che ogni programma venga eseguito per il programmatore come se fossimo nel modello sequenziale.
La soluzione a questo problema, in Linux, è la creazione dinamica di esecutori, detti processi.Ogni processo è come se fosse una macchina a se stante indipendente dalle altre, una macchina virtuale, cioè creata dal software.
Il processo è visto come una macchina virtuale:
- il programma eseguito da un processo può essere sostituito senza annullare il processo stesso, ovvero un processo può passare dall’esecuzione di un certo programma ad uno diverso.Dato che il processo rimane lo stesso anche se cambia il programma, le risorse rimangono e il nuovo programma può usarle.
- il processo possiede delle risorse, ad esempio una memoria, file aperti, terminale di controllo ecc…
Tutti i processi sono identificati da un PID(Process Identifier).Tutti i processi sono creati da altri processi a eccezione di init, cioè il primo processo creato all’avvio del SO.
Ogni processo(tranne init) possiede un processo parent che lo ha creato.
La memoria di un processo è costituita:
- segmento codice(text segment)
- segment dati(user data segment): sia dati statici che dinamici che a loro volta si dividono in dati allocati in stack(variabili locali delle funzioni) e dati dinamici allocati tramite malloc() in una zona detta heap.
- segmento di sistema(system data segment): dati che non sono gestiti esplicitamente dal programma in esecuzione, ma dal SO(es. tabella file aperti)
I principali servizi di Linux per la gestione di processi:
- terminare un processo figlio restituendo un codice di stato(terminazione) al padre
- generazione di processo figlio(child),copia del padre in esecuzione
- attesa della terminazione di un processo figlio
- sostituire il programma in esecuzione, cioè il segmento codice
FORK E EXIT:GENERAZIONE DEI PROCESSI
La fork crea un processo figlio identico al padre.Tutti i segmenti del padre sono duplicati nel figlio(codice, variabili, file, socket usati-segmento di sistema)
- nel processo padre la funzione fork restituisce il valore del pid del processo figlio appena creato
- nel figlio la fork restituisce il valore 0
- se restituisce -1 indica un errore e non è stato creato il processo
La exit() pone un termine al processo corrente.Un programma può terminare anche senza una invocazione diretta di exit(in tal caso invocata dal SO).
//creazione di un processo
//librerie da includere:
#include <stdio.h>
#include <sys/types.h>
#include <stdlib.h>
#include <unistd.h>
...int main(){
pid_t pid1;
pid1 = fork();//creazione di un processo identico
if(pid1 == 0){//codice del processo figlio
printf("SONO IL PROCESSO FIGLIO");
exit();
}
else{//codice del processo padre
printf("SONO IL PROCESSO PADRE");
exit();
}WAIT:ATTESA TERMINAZIONE CHILD
La wait() sospende l’esecuzione del processo che la esegue e attende la terminazione di un qualsiasi processo figlio; se un figlio è terminato prima che il padre esegua la wait, la wait non blocca nulla nel padre.
pid_t wait(int *) //PROTOTIPO
pid = wait(&stato) //ESEMPIO DI USOLa variabile stato assume il valore del codice di terminazione del processo figlio.Tale codice contiene una parte (gli 8 bit superiori) che può essere assegnato esplicitamente dal programmatore tramite la funzione exit nel modo descritto sotto; la parte restante è assegnata dal sistema operativo per indicare particolari condizioni di terminazione (ad esempio quando un processo viene terminato a causa di un errore).
void exit(int) // PROTOTIPO EXIT CON RESTITUZIONE STATO
exit(23) // ESEMPIO DI EXIT CON RESITUZIONE DI 23Se il processo che esegue la exit non ha più un processo padre (nel senso che il processo padre è terminato prima), lo stato della exit viene restituito all’interprete comandi.
Dato che il valore restituito dalla exit è contenuto negli 8 bit superiori, lo stato ricevuto dalla wait è lo stato della exit moltiplicato per 256.
C’è poi la funzione waitpid che invece aspetta un processo specificato(basta passare la variabile pid come parametro).
Inoltre, ipotizzare un preciso ordine di esecuzione è un grave errore perchè dipende dal Kernel del SO!
EXEC:SOSTITUZIONE DEL PROGRAMMA IN ESECUZIONE
La funzione exec sostituisce i segmenti codice e dati (di utente) del processo
corrente con il codice e i dati di un programma contenuto in un file eseguibile
specificato.Il
segmento di sistema non viene sostituito, quindi ad esempio i file aperti rimangono aperti e disponibili.
Il
processo rimane lo stesso e mantiene quindi lo stesso pid.
Si possono anche passare dei parametri al nuovo programma, tramite il meccanismo di passaggio standard dei parametri al main(argc e argv).
execl (char *nome_programma, char *arg0, char *arg1, ...NULL );- nome_programma: stringa che identifica l’eseguibile, quindi il suo pathname
- arg0,…argN sono puntatori a stringhe che verranno passate al main del nuovo programma lanciato in esecuzione. L’ultimo deve essere NULL per indicare la fine dei parametri.
Ecco come il main riceve i parametri:
void main(int argc, char * argv[])//argc= numero argomenti(dim argv), argv=array di parametriPer convenzione argv[0] contiene sempre il nome del programma lanciato in esecuzione.
THREAD
Come vedremo, in Linux, il thread è definito come un “Processo Leggero”.
A volte capita che attività eseguite da un calcolatore devono avere la possibilità di comunicare tra loro: il modello dei processi non va più bene perchè abbiamo detto che i processi sono delle macchine virtuali indipendenti tra loro e non permettono una comunicazione.
Allora la nozione di processo viene affiancata dalla nozione di thread, usati invece per attività fortemente cooperanti.I processi hanno meccanismi di comunicazione, ma sono complessi e limitati.Noi useremo i processi per attività che non comunicano tra loro.
I thread vengono creati all’interno di uno stesso processo, quindi condividono stesso spazio di indirizzamento e strutture dati.
Creare un thread è meno oneroso(in termini di risorse come il tempo macchina) di un processo e i thread possono condividere molte risorse rispetto ai processi.I thread sono detti anche processi leggeri.
Il modello di thread che noi seguiremo è quello adottato da Linux, POSIX(Portable Operating System Interface for Computing Environments).Il suo obbiettivo è la portabilità degli applicativi in ambienti diversi(che implementano sempre POSIX).Qui i thread sono chiamati Pthread
Per noi, parallelismo sarà equivalente a concorrenza, cioè due attività sono concorrenti o parallele se non è possibile stabilire a priori se un’istruzione di una attività è eseguita prima o dopo di un’istruzione dell’altra attività.
Si parla di parallelismo reale quando le istruzioni di due attività vengono eseguite effettivamente in parallelo da processori diversi.
I thread sono simili ai processi, possiamo considerare un thread un sottoprocesso che può esistere solo nell’ambito del processo che lo contiene:
- se un processo termina, tutti i suoi thread terminano anch’essi, è necessario quindi garantire che un processo non termini prima che tutti i thread abbiamo svolto il loro compito.
- si distingue ovviamente tra identificativo del processo(che contiene il thread) e identificativo del thread, che è di tipo pthread_t
- i thread possono andare in attesa di un evento(esempio I/O) in maniere indipendente:se un thread si pone in attesa, gli altri thread del processo possono essere nel frattempo eseguiti in modo da non bloccare l’intero processo
Funzioni per i thread:
- pthread_create():analoga alla fork, crea un thread che viene creato passandogli il nome di una funzione che deve eseguire
- pthread_join(): funzione di attesa, un thread può attendere la terminazione di un altro thread
- return:un thread termina quando termina l’esecuzione della funzione eseguita dal thread, o per un return oppure perchè sono state eseguite tutte le istruzioni
- esiste la possibilità di passare un codice di terminazione tra un thread che termina e quello che lo ha creato, se quest’ultimo ha eseguito una pthread_join per attenderlo
Il thread principale(o di default) è il main() del programma lanciato in esecuzione.
Quindi le variabili locali della funzione eseguita dal thread appartengono solo a quel thread perchè sono allocate sul suo stack.
Le variabili non allocate sulla pila, cioè le statiche e globali sono condivise tra i vari thread del processo.
CREAZIONE E ATTESA TERMINAZIONE DI UN THREAD
pthread_create ha 4 parametri:
- il primo parametro è l’indirizzo di una variabile di tipo pthread_t. In questa variabile verrà posto l’identificatore del thread creato
- il secondo parametro è un puntatore agli attributi del thread e può essere NULL
- indirizzo della funzione che il thread deve eseguire(chiamata thread_function)
- eventuale argomento che si vuole passare alla funzione, deve essere di tipo puntatore a void.Vista questa limitazione, per passare più parametri è necessario creare una struttura dati e passare l’indirizzo di questa
...int main(){
pthread_t thread1;
pthread_create(&thread1,NULL,&funzione,(void*)34);//esempio creazione di thread con passaggio del parametro 34
pthread_join(thread1,NULL);//attesa della terminazione del thread thread1
...PROGRAMMAZIONE CONCORRENTE
L’esistenza di diversi processi non altera il paradigma della programmazione sequenziale, perchè all’interno di un processo, l’esecuzione è sequenziale, ma le cose si complicano quando ci sono più attività eseguite in parallelo e si scambiano messaggi e dati tra loro. Questo perchè se pensiamo ad una variabile usata da più thread e un thread ha bisogno del valore di questa variabile, ma un thread improvvisamente lo cambia, possono crearsi errori…
Il modello di esecuzione di un processo è deterministico, cioè sappiamo dire l’ordine di esecuzione delle istruzioni.
Il modello di esecuzione dell’Hardware invece è non-deterministico, perchè la prossima istruzione che verrà eseguita può dipendere anche dal verificarsi di eventi il cui esatto istante di accadimento è imprevedibile(si pensi all’attesa di una periferica).
Un programma con thread multipli è non deterministico
#include <pthread.h>
#include <stdio.h>
void * tf1(void *arg)
{
printf("1");
printf("2");
printf("3");
return NULL;
}
void * tf2(void *arg)
{
printf("a");
printf("b");
printf("c");
return NULL;
}
int main(void)
{
pthread_t tID1;
pthread_t tID2;
pthread_create(&tID1, NULL, &tf1, NULL);
pthread_create(&tID2, NULL, &tf2, NULL);
pthread_join(tID1, NULL);
pthread_join(tID2, NULL);
printf("\nfine\n");
return 0;
}In questo caso non è possibile stabilire se viene stampato 1a2b3c o se 123abc ma di certo non potrà essere stampato a2b1c3, perchè l’esecuzione interna è sempre sequenziale.
MUTEX
Per ottenere un risultato corretto alcune sequenze di istruzioni non devono essere mescolate tra loro durante l’esecuzione. Chiameremo una sequenza di istruzioni di questo genere una sequenza critica e mutua esclusione la proprietà che vogliamo garantire a queste sequenze.
Una operazione/istruzione si dice
atomica se o viene eseguita completamente o non viene eseguita per niente ma non in modo concorrente.Le istruzioni assembly sono garantite essere atomiche, ma quelle C non è detto.
Mutua esclusione significa che un solo thread alla volta accede ad una risorsa condivisa.
Nei Pthread si usano i mutex per gestire la mutua esclusione.Un mutex è un blocco, ovvero un segnale di occupato che può essere attivato da un solo thread alla volta.Quando un thread attiva il blocco(lock), se un altro cerca di attivarlo, quest’ultimo viene messo in attesa fino a quando il primo thread non sblocca(unlock) il mutex.
Per creare un mutex, deve essere creata una variabile di tipo pthread_mutex_t, poi inizializzata tramite la funzione pthread_mutex_init.Il lock viene fatto con pthread_mutex_lock e l’unlock con pthread_mutex_unlock.
#include <stdio.h>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
int varGlob = 0;
pthread_mutex_t mutex;
void *tf1(void *argomenti){
pthread_mutex_lock(&mutex);
printf("A");
printf("B");
printf("C");
pthread_mutex_unlock(&mutex);
}
void *tf2(void *argomenti){
pthread_mutex_lock(&mutex);
printf("1");
printf("2");
printf("3");
pthread_mutex_unlock(&mutex);
}
int main(){
pthread_t thread1;
pthread_t thread2;
int input = 0;
pthread_mutex_init(&mutex,NULL);
pthread_create(&thread1,NULL,&tf1,&input);
pthread_create(&thread2,NULL,&tf2,&input);
pthread_join(thread1,NULL);
pthread_join(thread2,NULL);
return 0;
}In questo caso l’output sarà sempre ABC123 o 123ABC
DEADLOCK
Il deadlock tra due thread consiste in un’attesa reciproca infinita, per cui t1 attende che t2 sblocchi la risorsa critica e viceversa, ed essendo ambedue i thread bloccati, nessuno dei due potrà attuare l’azione che sblocca l’altro.Una volta verificatosi, è permanente ed è ovviamente una condizione indesiderata.Ecco un esempio:
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t mutex2 = PTHREAD_MUTEX_INITIALIZER;
void *thread1(void *arg) {
pthread_mutex_lock(&mutex1);
printf("Thread 1 ha acquisito mutex1\n");
// Simula qualche lavoro
pthread_mutex_lock(&mutex2); // Attesa attiva di mutex2
printf("Thread 1 ha acquisito mutex2\n");
pthread_mutex_unlock(&mutex2);
pthread_mutex_unlock(&mutex1);
pthread_exit(NULL);
}
void *thread2(void *arg) {
pthread_mutex_lock(&mutex2);
printf("Thread 2 ha acquisito mutex2\n");
// Simula qualche lavoro
pthread_mutex_lock(&mutex1); // Attesa attiva di mutex1
printf("Thread 2 ha acquisito mutex1\n");
pthread_mutex_unlock(&mutex1);
pthread_mutex_unlock(&mutex2);
pthread_exit(NULL);
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, thread1, NULL);
pthread_create(&tid2, NULL, thread2, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
return 0;
}SINCRONIZZAZIONE E SEMAFORI
A volte un thread deve attendere che un altro thread abbia raggiunto un certo punto di esecuzione prima di procedere.
Se ad esempio un thread fa 3 printf di A,B,C e un altro thread fa 3 printf di 1,2,3 e voglio ad esempio che le printf si alternino, ad esempio, A,1,B,2,C,3, si usano i cosiddetti semafori.Un semaforo è una variabile intera sulla quale si può operare solamente nel modo seguente:
- un semaforo viene inizializzato con un valore e poi può essere solamente incrementato o decrementato di 1(come un contatore). E’ una variabile di tipo sem_t che viene inizializzata con la funzione sem_init
- Per decrementare il semaforo si usa sem_wait().Se il valore è già a 0, il thread che esegue l’operazione wait viene bloccato fino a che un altro thread esegue un incremento(la wait si sblocca e il thread bloccato procede)
- Per incrementare il semaforo si usa invece sem_post(); se ci sono altri thread in attesa sullo stesso semaforo uno di questi viene sbloccato e può procedere(e il semaforo viene decrementato nuovamente).
Ecco come interpretare il valore di un semaforo:
se >0 rappresenta il numero di thread che lo possono decrementare senza andare in wait
se <0 rappresenta il numero di thread che sono bloccati in attesa
se =0 non ci sono thread in attesa, ma il prossimo che eseguirà una wait andrà in attesa
sem_t semaforo;//dichiarazione del semaforo.Deve essere una variabile globale
sem_init(&semaforo,0,0)//esempio di inizializzazione di un semaforo nel MAINIl secondo parametro di init è sempre 0 e il terzo indica il valore iniziale(se posto a 1 funziona come un mutex).
Quando il thread termina la sequenza critica esegue una post e questa operazione sblocca un altro thread già in attesa oppure riporta il semaforo al suo stato iniziale, il che indica che la sequenza critica è libera.
Un esempio di applicazione pratica dei semafori è il buffer nel quale uno o più thread produttori scrivono caratteri e uno o più thread consumatori leggono caratteri.Il semaforo pieno blocca il thread produttore fino a quando il thread consumatore non ha prelevato il carattere; il semaforo vuoto blocca il consumatore fino a quando il produttore non ha scritto il carattere.
Cos’è un buffer? un buffer è un’area di memoria temporanea usata per immagazzinare dati temporaneamente mentre vengono trasferiti da un’origine a una destinazione.E’ come una zona di transito dove i dati possono essere temporaneamente salvati prima di essere processati o usati in un altro modo.
In breve è una zona di memoria in cui leggo e scrivo dati(array ad esempio): con i semafori, appena termina la scrittura, si effettua la lettura dei dati.
Kernel Linux
INTRODUZIONE A LINUX
Linux è un SO Unix(un sistema il cui sviluppo iniziò negli anni Settanta).L’obbiettivo di Linux, nome del kernel in realtà, era quello di creare un sistema adatto ai personal computer per ISA(Instruction Set Architecture) Intel 386.
Linus Torvald, creatore di Linux ideò il suo sistema partendo da zero e basandosi sui principi di funzionamento di Unix, sistema che apparteneva però ad AT&T e il suo codice non poteva essere visto.
L’evoluzione della dimensione del codice di Linux(il codice del kernel passa da 10 righe nel 1991, prima versione a 15 803 righe nel 2013) è dovuta all’inarrestabile evoluzione dell’Hardware: i gestori delle periferiche occupano più del 50% del codice complessivo di Linux.
Preemption:la capacità del SO di interrompere un processo, in due modi, quello di sostituirlo con un altro processo, o di sospenderlo solo temporaneamente.
La funzione del SO è quella di gestire l’hardware e rendere semplice il suo impiego da parte dei programmi applicativi; la funzione principale è quella di creare e gestire i processi.
Come già detto il supporto si basa sull’utilizzo di processi come macchine virtuali che eseguono programmi.
Durante l’esecuzione i programmi possono anche richiedere al processo delle particolari funzioni dette system services(servizi di sistema).Quelli fondamentali sono:
- servizi di creazione di processi e esecuzione dei programmi, fork, exec, wait, exit
- servizi collegati a comunicazione tra diversi processi e la segnalazione di eventi ai processi
- servizi di accesso ai file(open, close, read, write, lseek, ecc…) grazie alla nozione di file speciale, possono accedere alle periferiche
Per permettere all’utente di interagire con il sistema c’è l’interprete dei comandi(shell) o l’interfaccia grafica(GUI).
PROCESSI E THREAD IN LINUX
In Linux, i Thread sono realizzati come particolari tipi di processi, detti Processi Leggeri(lightweight process).Terminologia:
- processo leggero: un processo creato per rappresentare un thread
- processo normale
- task o processo: un generico processo
I thread appartenenti a uno stesso processo hanno lo stesso PID.Poi c’è un’altra classificazione che viene fatta, il thread group id, che non è altro che un identificatore di un gruppo di processi leggeri appartenenti a uno stesso processo normale.In risposta alla richiesta getpid() tutti i processi del gruppo restituiscono il PID del thread group leader, cioè del primo processo del gruppo (TGID).
restituisce il PID del processo, getpid( ) restituisce il TGID che è identico per i Processi che appartengono allo stesso gruppo.
Il SO svolge la fondamentale funzione di far si che i processi vengano eseguiti in parallelo, come se ci fosse un processore per ogni processo(virtualizzazione del processore).
Il sistema operativo deve far eseguire al processore i programmi dei diversi processi in alternanza.La sostituzione di un processo in esecuzione con un altro è detta Commutazione di Contesto(Context Switch).Con Contesto intendiamo l’insieme di informazioni relative ad ogni processo che il SO mantiene.
E’ l’operazione più importante svolta dal kernel e richiede di risolvere due problemi:
- Quando deve avvenire
- Quale processo scegliere tra quelli disponibili
Si noti inoltre la differenza tra multiprocessore e multicore: un sistema multiprocessore è caratterizzato da più processori separati(presenti su singoli chip o su schede separate); multicore significa che ci sono più core di elaborazione integrati nello stesso chip.
L’esecuzione di un programma può essere sospesa per due motivi:
- il programma deve attendere una periferica o un dato esterno
- è scaduto il quanto di tempo assegnato al processo
Il componente del SO che decide quale processo mandare in esecuzione è lo Scheduler.
Il comportamento dello Scheduler realizza la politica di Scheduling ed è orientato a garantire le seguenti condizioni:
- i processi più importanti devono essere eseguiti prima di quelli meno importanti
- i processi di pari importanza devono essere eseguiti in maniera equa, nessun processo dovrebbe attendere il proprio turno di esecuzione per un tempo molto superiore agli altri
LINUX è time sharing, cioè fa eseguire un programma per un certo tempo e poi sospende l’esecuzione(preemption) per permettere l’esecuzione di altri processi.Il SO tenta di garantire che il processore esegua i programmi in maniera equa, senza essere monopolizzato da un unico programma.
SISTEMI MULTI-PROCESSORE SMP
I calcolatori moderni sono dotati in genere di più processori e il SO ne deve tener conto.Il tipo di architettura meglio supportata da Linux è la SMP(Symmetric Multiprocessing).In una architettura SMP…
- 2 o più processori identici su socket(die) diversi collegati a una memoria centrale(non hanno in comune la cache)
- hanno tutti accesso a tutti i dispositivi periferici
- controllati da un singolo sistema operativo e vengono solitamente considerati identici
La SMP è fatta cosi: esistono due o più processori identici collegati a una singola memoria centrale, che hanno tutti accesso a tutti i dispositivi periferici e sono controllati da un singolo sistema operativo, che li tratta tutti ugualmente, senza riservarne nessuno per scopi particolari. Nel caso di processori multi-core, il concetto di SMP si applica alle singole core, trattandole come processori diversi.
Linux alloca ogni task a una singola CPU in maniera statica e nello svolgere una riallocazione dei task tra le CPU solo quando, in un controllo periodico, il carico della CPU risulta sbilanciato e fa quindi un load balancing.
Lo spostamento di un task da una CPU a un’altra richiede di svuotare la cache, introducendo un ritardo nell’accesso in memoria finchè i dati non sono stati caricati nella cache della nuova CPU.
La funzione get_current() restituisce un riferimento al descrittore del processo corrente del processore che lo esegue.
KERNEL NON PREEMPTABLE
Linux, nella sua versione normale, applica la regola che è proibita la preemption quando un processo esegue servizi del SO.Per questo si dice che il Kernel di Linux è non-preemptable.
E’ però possibile compilare il kernel con l’opzione CONFIG_PREEMPT per ottenere una versione in cui il kernel può essere preempted(il motivo di compilarlo in questa modalità riguarda i sistemi real time e le politiche di scheduling che vedremo in seguito).
Il SO deve evitare che un processo possa svolgere azioni dannose per il sistema stesso, attraverso meccanismi Hardware che vedremo.
Il SO deve gestire le risorse fisiche disponibili in maniera efficiente. Le risorse che il sistema operativo deve gestire sono le seguenti:
- processore: che deve essere assegnato all’esecuzione dei diversi processi e del SO stesso
- memoria: deve contenere i programmi(codice e dati) eseguiti nei diversi processi e il SO
- periferiche:devono essere gestite in funzione delle richieste dei diversi processi
Le periferiche in Linux sono viste come dei file speciali, in modo che il programma non deve conoscere i dettagli realizzativi della periferica.Ovviamente per ogni periferica c’è un diverso gestore(device driver).
Nasce allora l’esigenza di poter aggiungere al SO i software di gestione di nuove periferiche che potrebbero essere aggiunte, questo software è il gestore di periferica(il cosiddetto driver).Allo stesso tempo si vuole però che sul SO siano installati solo i driver necessari ed effettivamente usati, altrimenti la dimensione del SO aumenterebbe inutilmente.
Allora sono stati introdotti i kernel_modules, che permettono di aggiungere driver senza dover ricompilare l’intero sistema. Inoltre, lo spazio di indirizzamento messo a disposizione dei moduli è doppio rispetto allo spazio di indirizzamento del sistema base.Inoltre questi moduli possono essere inseriti e rimossi dinamicamente nel sistema.
/* inclusioni minimali per il funzionamento di un Kernel module */
#include <linux/init.h>
#include <linux/module.h>
/* Questa è la funzione di inizializzazione del modulo,
* che viene eseguita quando il modulo viene caricato */
static int __init test_init(void){
/* printk sostiuisce printf, che è una funzione di libreria * non disponibile all'interno del Kernel */
printk("Inserito modulo test\n");
return 0;
}
/* Questa macro è contenuta in <linux/module.h> e comunica al
* sistema il nome della funzione da eseguire come inizializzazione */
module_init(test_init);
/* stesse considerazioni per axo_exit e la macro module_exit */
static void __exit test_exit(void)
{
printk("Rimosso modulo test\n");
module_exit(test_exit);
/* MODULE_LICENSE informa il sistema relativamente alla licenza con la quale
* il modulo viene rilascitao - ha effetto su quali simboli
* (funzioni, variabili, ecc...) possono essere acceduti */
MODULE_LICENSE("GPL");
/* Altre informazioni di identificazione del modulo */
MODULE_AUTHOR("Edoardo");
MODULE_DESCRIPTION("prints hello");
MODULE_VERSION("");#!/bin/bash
# attiva la visualizzazione dei comandi eseguiti
echo "build module"
# esegui compilazione e link (tramite makefile)
make
echo "remove and insert module"
# inserisci il modulo (ubuntu usa sudo per operazioni che richiedono diritti di amministratore)
sudo insmod ./test.ko
# ricevi i messaggi del sistema (che normalmente non compaiono a terminale e inviali al file console.txt (creandolo o svuotandolo)
dmesg|tail -1 >console.txt # rimuovi il modulo
sudo rmmod test
# ricevi i messaggi e appendili al file console.txt
dmesg|tail -1 >>console.txt
DIPENDENZA DALL’ARCHITETTURA HARWARE
Linux è scritto in C e compilato(e linkato) con il compilatore gnu gcc; questo fatto semplifica molto la sua portabilità sulle diverse piattaforme Hardware per le quali esiste il compilatore.L’adattamento alle diverse architetture però non è totalmente delegabile al compilatore, infatti alcune funzioni del SO richiedono di tener conto del tipo di Harware sul quale sono implementate.I file che contengono dipendenze dall’architettura sono sotto la cartella <linux/arch>.Si considera qui come riferimento l’architettura x86-64, una ISA definita nel 2000.
L’informazione relativa ad ogni processo è rappresentata in delle strutture dati, tenute dal SO. Per ogni processo in esecuzione, una parte del contesto, detta Contesto Hardware è rappresentata dal contenuto dei registri della CPU.Anche questa parte deve essere salvata nelle strutture dati quando il processo sospende l’esecuzione.
Le strutture dati usate per rappresentare il contesto di un processo sono due:
- DESCRITTORE DEL PROCESSO: una struttura dati, forse la più importante del kernel.L’indirizzo del descrittore costituisce un identificatore univoco del processo
- PILA SO DEL PROCESSO: la sPila, è una pila di sistema operativo.Ne esiste una per processo
DESCRITTORE DEL PROCESSO
La struttura di un descrittore è definita in <linux/kernel/sched/sched.h>.Ecco una versione semplificata:
struct task_struct {
pid_t pid;
pid_t tgid;
volatile long state; /* ‐1 unrunnable, 0 runnable, >0 stopped */
void *stack; //puntatore alla sPila del task
/* CPU‐specific state of this task */
struct thread_struct thread;
// variabili utilizzate per Scheduling – vedi capitolo relativo
int on_rq;
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
// puntatori alle strutture usate nella gestione della memoria –
//vedi capitolo relativo
struct mm_struct *mm, *active_mm;
// variabili per la restituzione dello stato di terminazione
int exit_state;
int exit_code, exit_signal;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
...
}Questa struttura viene allocata dinamicamente nella memoria dinamica ogni volta che viene creato un nuovo processo.
Negli esempi indichiamo i processi con un nome che ipotizziamo essere anche il nome di una variabile contenente il riferimento al suo descrittore.
Dato un processo di nome PROCESSO_A, lo indicheremo con:
struct task_struct *PROCESSO_A;PROCESSO_A->pid indica il campo pid del descrittore del processo P.La funzione get_current() restituisce un puntatore al task corrente.
struct thread_struct {
...
unsigned long sp0;//puntatore a base di sPila del processo
unsigned long sp; //puntatore alla pila di modo S (posizione corrente)
unsigned long usersp; // puntatore alla pila di modo U (idem)
...
}Questo campo contiene il contesto hardware della CPU di un processo quando non è in esecuzione.Questa struttura dipende dall’hardware, quindi la si trova nella directory arch.
Il codice originale di Linux è complesso anche per il fatto che il C utilizzato non è soltanto quello del gcc standard.
MECCANISMI HARDWARE DI SUPPORTO
Alcune note su x64:
- x64 salva il valore di ritorno sullo stack durante una chiamata a funzione, non in un registro come RISC-V o MIPS.Quindi l’istruzione che fa il salto a funzione decrementa SP(per fare quindi spazio sullo stack, che ricordiamo crescere da indirizzi alti a indirizzi bassi),PC viene incrementato e salvato sullo stack(per l’indirizzo di ritorno) e poi quando la funzione ritorna, incrementa SP.
- i registri sono a 64 bit, PC del RISCV è chiamato RIP in x64, SP in x64 è chiamato RSP
- push e pop sullo stack sono eseguiti da una sola istruzione assembler
- lo stack cresce sempre da indirizzi alti verso indirizzi bassi
Il SO richiede che l’hardware utilizzi delle informazioni in modo automatico.Per questo infatti esistono dei registri e strutture dati, anche leggibili o scrivibili dal software.Queste strutture sono dette Strutture dati ad Accesso Hardware.Sono strutture a cui il SO può accedere e fare modifiche e l’HW accede a queste in modo autonomo, senza istruzioni.
Supponiamo per semplicità che esista un registro detto Process Status Register(PSR) che contiene le informazioni di stato che caratterizzano la situazione del processore, tranne alcune informazioni per le quali indicheremo esplicitamente dei registri dedicati a contenerle.
In realtà in x64 questo registro non esiste, ma il contenuto dei registri PSR,USP,SSP ecc che noi useremo è contenuto in una struttura dati detta Task State Segment(TSS) accessibile tramite un descrittore detto TSSD contenuto nella GDT(Global Descriptor Table).PSR è un registro contenuto però realmente nell’architettura ARM.
Nel PSR ci sono informazioni come il bit di stato(se il processore è in modalità utente o kernel), carry, overflow, presenza di interrupt ecc…
Il processore può funzionare in due modalità: il modo Utente (U, o “non privilegiato”) e modo Supervisore(S, o kernel/privilegiato).In modo S può eseguire tutte le proprie istruzioni macchina e accedere a tutta la memoria.Quando è in modo U ha accesso solo a una parte del set di istruzioni e può accedere solo a una parte della memoria.Il SO è eseguito in modalità S.
In x64 in realtà ci sono 4 modi di funzionamento ma Linux ne prevede solo due e quindi si considerano solo S o U.Inoltre lo stato attuale del modo di funzionamento è memorizzato in un registro apposito inaccessibile dal sofware.Il registro è detto CPL(Current Privilege Level) ed è memorizzato in un registro interno del processore inaccessibile dal software.Noi supponiamo che il CPL sia memorizzato in PSR.
CHIAMATA AL SUPERVISORE
Quando un processo necessita di un servizio del SO deve eseguire una SYSCALL, una istruzione che fa un salto a una funzione del SO.E’ una vera e propria chiamata di funzione.
SYSCALL sostituisce ovviamente oltre al PC, anche il valore del PSR, salvando i vecchi valori sullo stack. I valori nuovi vengono prelevati da una struttura dati ad accesso HW, posta ad un indirizzo noto dall’HW ovviamente.Tale struttura è il vettore di syscall.
Quando viene eseguita SYSCALL…
- PC viene incrementato e il valore viene salvato sullo stack(incrementato perchè quando la funzione ritorna deve restituire il controllo sull’istruzione successiva alla chiamata a funzione)
- PSR corrente viene salvato sullo stack
- nel PC e nel PSR vengono caricati i valori presenti sul Vettore di Syscall
Quindi l’indirizzo del salto viene determinato dalla CPU tramite il vettore di syscall. Linux inizializza questa struttura dati durante la fase di avviamento con l’indirizzo della funzione system_call(), il punto unico di entrata per tutti i servizi di sistema.
Quindi il vettore di syscall contiene gli indirizzi di tutte le funzioni associata a ciascun servizio di sistema, richiesto tramite istruzione SYSCALL.
Logicamente, SYSCALL è una istruzione non privilegiata e quindi eseguibile in modo U, altrimenti non sarebbe utilizzabile dai processi.Dopo la sua esecuzione il processore passa subito in modo S ed è l’unico modo per un programma di passare al modo S.
Per il ritorno, all’interno del codice SO c’è una istruzione di ritorno, la SYSRET:
- viene caricato il valore presente sullo stack nel PSR(e viene quindi fatto il pop del PSR dallo stack, viene quindi incrementato SP)
- nel PC viene caricato il valore presente sullo stack e viene fatto il pop di PC dallo stack.
MEMORIA DEL SO
Quando il processore è in modo U non deve accedere alle zone di memoria del SO.Invece quando è in modo S deve poter accedere a tutta la memoria.
Quindi per far si che questo accada, lo spazio di indirizzamento virtuale viene diviso a metà in due sottoinsiemi distinti, quello di modo U e di modo S:
Lo spazio di indirizzamento, essendo i registri da 64 bit sarebbe 2^64 byte massimo in teoria, ma in realtà l’architettura limita questo spazio a 2^48 byte, cioè 256Tb. Allora questo spazio è diviso in 128 e 128: nei primi 2^47 byte c’è lo spazio di modo U e nella seconda metà superiore di 2^47(128Tb) c’è lo spazio di modo S.
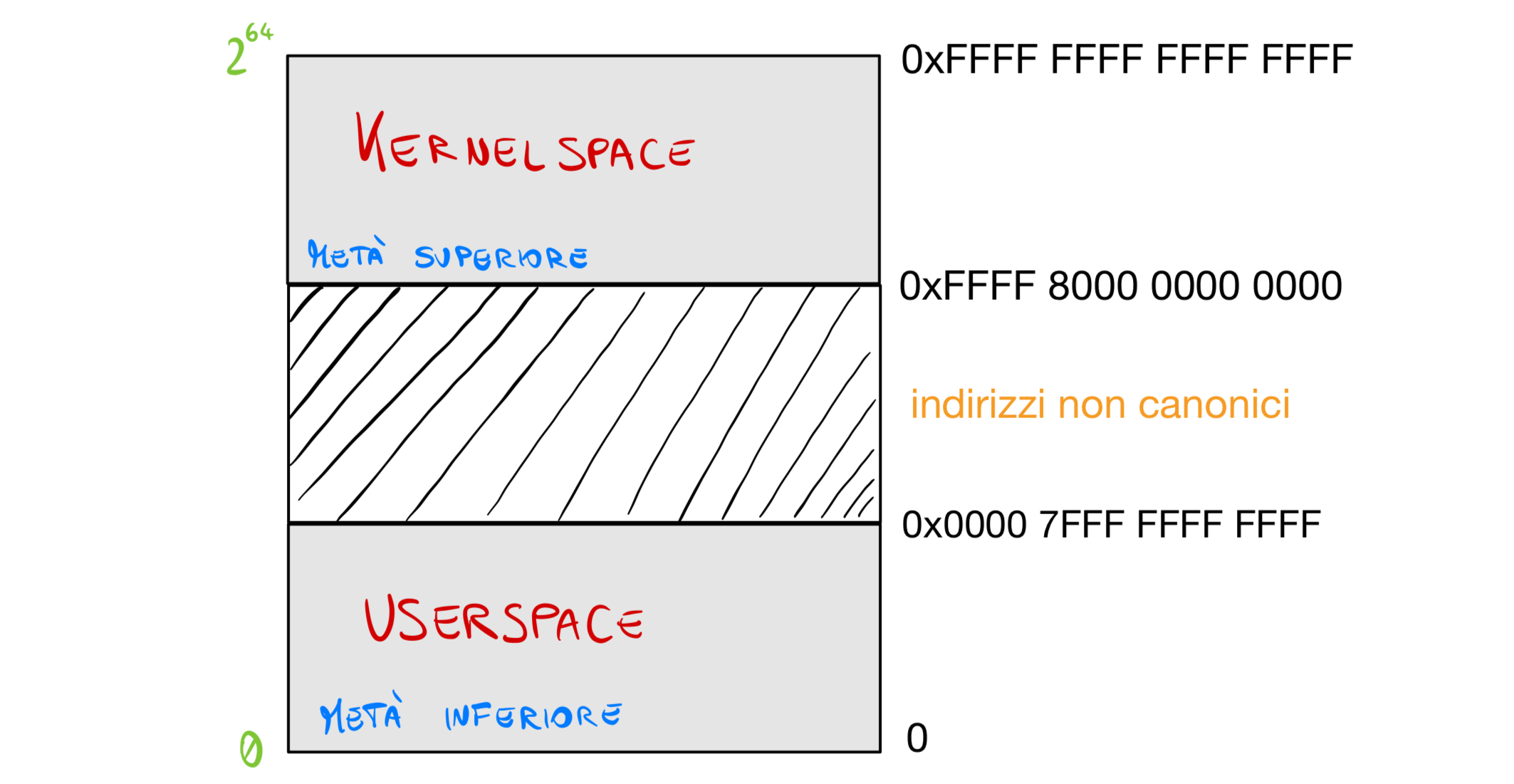
La memoria in Linux è gestita tramite paginazione. Ciò significa che la memoria è divisa in unità dette pagine, di dimensione 4Kb(l’amministratore di sistema può cambiare questo valore).Le pagine sono quindi l’unità di allocazione della memoria(ad esempio anche dell’heap o dello stack).
Questo per ogni programma, quindi ogni programma ha associata una memoria cosi organizzata.
Ogni indirizzo che il processore produce è detto indirizzo virtuale e deve essere trasformato ogni volta in un indirizzo fisico per accedere alla memoria (mappatura).La mappatura è descritta dalla Tabella delle Pagine. In seguito approfondiremo questo argomento.
CAMBIO DI MODALITA’ CPU KERNEL←→NON SUPERVISIOR
Lo stack usato implicitamente dalla CPU è puntata dallo SP(registro Stack Pointer).Per realizzare il SO è necessario fare in modo che lo stack usato durante il funzionamento in modo S sia diverso da quella usato nel modo U.
Quando la CPU cambia modo di funzionamento deve cambiare anche il valore di SP e puntare alla sPila.Ad esempio un programma che fa una SYSCALL passerà da modo U a modo S. Quindi, nel fare il cambio di modalità deve cambiare anche il valore di SP e farlo passare dal puntare alla uPila(stack utente, cioè quello puntato dai processi, in modo U) al farlo puntare alla sPila.
Ovviamente quando si passa da modo U a modo S deve essere salvato sulla sPila il valore del PC di ritorno a modo U e viceversa quando accade il contrario.
E’ necessario però che l’HW possa determinare automaticamente il valore di SP in modo S da sostituire a quello di modo U.
Seguendo un modello semplificato, supponiamo che ci sia semplicemente una struttura dati ad accesso HW contenente due celle di memoria, lo USP(User Stack Pointer) e lo SSP(System Stack Pointer), con SSP che contiene il valore di SP da caricare in modo S.Al contrario USP contiene lo SP di modo U e salvato al momento del passaggio a modo S.
Le operazioni svolte da SYSCALL sono:
- salva il valore corrente di SP in USP
- carica in SP il valore presente in SSP(passaggio a sPila)
- salva su sPila il PC di ritorno al programma chiamante
- salva su sPila il valore del PSR del chiamante
- carica in PC e PSR i valori presenti nel vettore di syscall
SYSRET poi fa le operazioni inverse, cioè carica in PSR il valore presente in sPila, carica in PC il valore che è sulla sPila e carica sullo SP il valore presente in USP(passaggio a uPila).
Linux associa ad ogni processo una diversa Tabella delle Pagine; in questo modo gli indirizzi virtuali di ogni processo sono mappati su aree che sono indipendenti dalla memoria fisica.Deve esistere un meccanismo per passare quindi da mappatura virtuale a fisica.
In x64 c’è il registro CR3(control register) che contiene il punto di partenza della tabella delle pagine usata per la mappatura degli indirizzi.
INTERRUPT
L’interrupt(argomento trattato nella parte di architettura dei calcolatori) è un segnale, dovuto a un evento rilevato dall’HW, ad esempio proveniente da una periferica(ad esempio il buffer della tastiera che si è riempito).Ad ognuno è associata una particolare funzione detta gestore dell’interrupt o routine di interrupt, che fa parte del SO.Quando il processore riceve un interrupt quindi interrompe l’esecuzione e passa ad eseguire la funzione associata a quel segnale e quando questa termina si ritorna all’esecuzione del programma interrotto.
E’ logico quindi pensare che come per ogni chiamata a funzione bisogna salvare dei valori sullo stack.Le routine di interrupt sono completamente asincrone rispetto al programma interrotto, come le funzioni dei thread e quindi vanno trattate con i principi della programmazione concorrente.
E’ analogo alla SYSCALL, infatti si deve sempre passare da modo U a modo S e si devono salvare le informazioni per il ritorno. A effettuare il ritorno(e quindi anche S→U) al processo interrotto c’è l’istruzione IRET.
Analogamente al vettore di SYSCALL c’è una struttura dati ad accesso HW detta Tabella degli Interrupt, in cui ci sono dei vettori di interrupt costituiti da una coppia di <PC,PSR> corrispondenti quindi all’indirizzo PC della routine e al suo valore di PSR.Quindi c’è un meccanismo che converte un interrupt in un corrispondente vettore di interrupt.
L’inizializzazione di questa tabella è fatta sempre all’avvio del SO.Si possono anche verificare interrupt annidati, quindi mentre si esegue una routine può arrivare un altro interrupt.
Gli interrupt sono utili anche per gestire eventuali errori, come un accesso ad aree di memoria non consentite o una divisione per 0, quindi c’è una routine anche per gestire gli errori.Un esempio tipico di gestione è la terminazione forzata(abort) del programma che ha causato l’errore.
Siccome abbiamo detto che possono esserci degli interrupt nidificati, è opportuno pensare che a volte si dovrebbe bloccare una routine di interrupt per eseguirne una più urgente.Quindi, ricordando che a ogni routine è assegnato anche un PSR, si utilizza questo meccanismo:
- al processore è assegnato un livello di priorità, scritto nel PSR, che può essere modificato tramite istruzioni macchina che modificano il PSR
- un interrupt viene accettato e quindi eseguita la routine solo se il suo livello di priorità è superiore al livello di priorità del processore in quel momento, altrimenti l’interrupt viene tenuto in sospeso fin quando non scende la priorità del processore
Approfondimento: i sorgenti di Linux vengono compilati e collegati come se fosse un normale eseguibile, ma il suo formato non è proprio un eseguibile perchè questi sono caricati proprio dal SO, invece il SO deve essere in grado di avviarsi da solo(bootstrap).Inoltre nota che syscall è una funzione in C, mentre SYSCALL è un’istruzione macchina.
PROGRAMMA→CHIAMATA DI LIBRERIA(SERVIZIO SO)→FUNZIONE RUNTIME(glibc)→syscall(C)→SYSCALL(assembly)
glibc è una libreria che contiene la chiamata di sistema(fork, open, ecc…).
GESTIONE DEI PROCESSI
Ogni processo può trovarsi in due stati:
- ATTESA: un processo in questo stato non può essere messo in esecuzione, perchè deve attendere il verificarsi di un certo evento, per esempio sta aspettando la risposta di una periferica
- PRONTO: un processo pronto è un processo che può esser messo in esecuzione se lo scheduler lo seleziona tra i process in stato di pronto.Tra questi, uno è in esecuzione, cioè il processo corrente.Questa informazione si trova nel descrittore del processo.
Il processo in esecuzione passa in abbandona tale stato in due casi:
- quando un servizio di sistema richiesto deve porsi in attesa di un evento, allora passa in stato di attesa.Un processo si pone in attesa quando è in esecuzione un servizio di sistema per suo conto
- quando il SO decide di sospendere l’esecuzione a favore di un altro processo(preemption), allora il processo passa in stato di pronto
SCHEDULER
E’ quel componente software del SO che decide quale dei processi mettere in esecuzione. Svolge principalmente due funzioni:
- sceglie quale processo deve essere messo in esecuzione, quando, per quanto tempo.Cioè la politica di scheduling
- esegue il Context Switch, quindi la sostituzione del processo corrente con un’altro che si trova in PRONTO
Vediamo in questa parte dell’articolo la funzione che esegue il Content Switch, cioè la funzione schedule() dello scheduler.
Lo scheduler gestisce una struttura dati fondamentale per ogni CPU: la runqueue. Essa contiene a sua volta due campi:
- un puntatore al process descriptor(task_struct) del processo corrente, detto CURR
- una lista di puntatori ai descrittori di tutti i processi pronti, detta RB
Ad ogni processo viene assegnato uno stack di 2 pagine(8Kb).Siccome il SO tiene una sPila per ogni processo, per cui bisogna salvare SSP e USP durante un cont. switch.
Infatti il descrittore di processo contiene anche un campo sp0 che contiene l’indirizzo della base della sPila, il SO mette qui un valore quando il programma viene lanciato; sp contiene invece il valore di SP salvato al momento in cui il processo ha sospeso l’esecuzione.
Il context switch viene effettuato cosi:
- quando il processo è in modo U, sPila è vuota e SSP ha il valore di base preso da sp0(dal descrittore del processo)
- quando la CPU passa al modo S in USP viene messo il valore corrente di sp(salvando l’indirizzo della uPila)
- se durante l’esecuzione in modo S viene eseguita una commutazione di contesto,USP viene salvato sulla sPila del processo corrente e poi il valore corrente di SP viene salvato nel campo sp del descrittore del processo corrente.Quando il processo poi riprenderà l’esecuzione SP verrà ricaricato dal campo sp del descrittore, puntando quindi alla cima di sPila
- USP verrà ricaricato prendendolo dalla sPila
- SSP verrà ricaricato prendendolo dal sp0 del descrittore
Se durante l'esecuzione in modo S viene seguita una commutazione di contesto, Linux opera così:
- salva USP(che contiene il valore di SP quando eseguiva in U) sulla cima della sPila di del processo P
- Salva SP(valore attuale nella CPU in modo S con con la posizione della cima della sPila di P) nel campo thread.sp del descrittore di P
Dove P è un generico processo.quando P riprende, a seguito di un'altra commutazione di contesto:
- SP verrà ricaricato da thread.sp del descrittore e quindi punterà alla cima della sPila di P(dove c'era USP)
- USP verrà ricaricato prendendolo dalla sPila
- SS P verrà ricaricato da thread.sp0 del descrittore di P
GESTIONE DEGLI INTERRUPT
La gestione dell'interrupt segue queste regole:
- quando c'è un interrupt ovviamente c'è sempre un processo in esecuzione.però possono verificarsi queste condizioni:
- L'interrupt interrompe un servizio di sistema in esecuzione
- L'interrupt interrompe una routine relativa ad un interrupt che ha priorità inferiore
- L’interrupt interrompe il processo mentre funziona in modo non privilegiato
- In tutti questi casi la routine svolge la propria funzione funzione senza disturbare il processo che già è in esecuzione e questo non viene mai sostituito durante l'esecuzione dell'interrupt
- Se l'interrupt è associato a un evento sul quale un certo processo era in attesa allora questo deve essere risvegliato passandolo da attesa pronto in modo che possa essere eseguito
si dice che la routine è trasparente cioè che il processo non viene disturbato ed è quindi ancora associato alla CPU e il SO esegui il codice della routine.
Un primo problema che emerge è quello di gestire un processo che è in stato di attesa, si verifica un evento che lo passa in stato di pronto, detto anche di Wake Up. Si noti che è un dato istante, potrebbe esserci più di un processo in attesa di uno stesso evento.
La problematica è resa più complessa dal fatto che ci sono diverse categorie di eventi che possono generare un'attesa e che richiedono una gestione diversa:
- attesa dello scadere di un timeout
- terminazione di un figlio
- attesa di un I/O
- attesa dello sblocco di un Lock
La scadenza di un timeout e la terminazione di un figlio non possono essere gestiti con una coda, in seguito vedremo il perché.
Una waitqueue è una lista contenente descrittori dei processi che sono in attesa di un evento.una Waitqueue viene creata ogni volta che vogliamo mettere dei processi in attesa di un evento, quindi conterrai descrittori di questi processi. L’indirizzo della waitqueue costituisce l'identificatore dell'evento. Ecco come può essere definita una coda come variabile globale:
DECLARE_WAIT_QUEUE_HEAD nome_codaPer mettere in attesa un processo è necessario indicare due parametri, cioè la coda ed una condizione. In alcuni casi conviene risvegliare tutti i processi presenti nella coda, in altri casi conviene risvegliarne uno solo(ad esempio se la risorsa può essere utilizzata da un solo processo).
I processi vengono inseriti in una Waitqueue che:
- ha un flag che indica se il processo in attesa esclusiva oppure no(cioè se deve essere risvegliato un solo processo l'attesa è esclusiva altrimenti non è esclusiva)
- I processi in attesa esclusiva sono inseriti a fine coda
Quindi la routine risveglia tutti tutti i processi dall'inizio della lista fino al primo processo in attesa esclusiva.ricordiamo che c'è una Waitqueue per ogni evento.
Permette un processo in in attesa esclusiva si utilizza la funzione wait_event_interruptible(), mentre per metterlo in attesa non esclusiva wait_event_interruptible().
la funzione fornita dal kernel per svegliare i processi in attesa su una certa coda, è
wake_up(wait_queue_head_t * wq)Che risveglia tutti i tasche in attesa non esclusiva è un solo tasche in attesa esclusiva sulla coda wq e per ogni task vengono svolte due operazioni:
- lo elimina dalla waitqueue e lo pone nella runqueue
- Cambia lo Stato da attesa a pronto
risvegliando dei processi questa funzione può creare una situazione in cui il processo corrente dovrebbe essere sostituito con una nuova, appena svegliato e con maggiori diritti di esecuzione.
Questa però non invoca mai mai direttamente schedule, se il nuovo task aggiunto alla runqueue ha diritto di sostituire quello corrente, wakeup pone a uno il flag TIF_NEED_RESCHED. Dopodiché schedule verrà invocata appena possibile.
SEGNALI E ATTESA INTERROMPIBILE
Un segnale è un avviso asincrono inviato dal sistema operativo ad un processo. Esso è identificato da un numero da 1 a 31.
Un signal causa l'esecuzione di un'azione da parte del processo che lo riceve. L'azione può essere svolta soltanto quando il processo processo viene in esecuzione in modo U.
Se il processo definito una propria funzione destinata a gestire quel segnale, questa viene eseguita, altrimenti viene eseguito il DEFAULT SIGNAL HANDLER.
La maggior parte dei segnali può essere bloccata dal processo, un segnale bloccato può rimanere pendente fino a quando non viene sbloccato.ci sono due segnali che non possono essere mai bloccati dal processo:
- SIGSTOP: sospende il processo per poi riprenderlo più tardi
- SIGKILL: termina immediatamente il processo
ci sono segnali che ad esempio possono essere inviati a causa di una particolare combinazione da tastiera, ad esempio CTRL C che invia il segnale SIGINT(terminazione del processo).
Ci possono essere dei casi in cui un segnale viene inviato quando il processo è in esecuzione in modalità Kernel quindi in questi casi viene processato immediatamente il ritorno al modo utente. Se il segnale viene inviato un processo pronto ma non in esecuzione viene tenuto sospeso finché il processo non torna in esecuzione.
Se il segnale viene inviato un processo in stato di attesa invece ci sono due possibilità che dipendono dal tipo di attesa:
- se l'attesa è interrompibile(stato TASK_INTERRUPTIBLE), il processo viene immediatamente risvegliato
- Altrimenti il signal rimane pendente
Si noti nel caso di attesa interro il processo può essere risvegliato senza che l'evento su cui era in attesa si sia verificato. Il Linux ci sono le seguenti funzioni che mettono in attesa un processo:
- wait_event(coda, condizione)- non da signal, neppure SIGKILL
- wait_ event_ killable(coda, condizione)-interrompibile solo da SIGKILL
- wait_ event_ interruptible(coda, condizione)- interrompibile da tutti i segnali
Utilizzeremo però solo le wait_event_interruptible(ATTESA coincide con TASK_INTERRUPTIBLE)
Un processo potrebbe andare però in attesa infinita, quindi Linux dà la possibilità di indicare i processi inseriti in una coda d'attesa come interrompibili o non interrompibili in maniera maniera asincrona. Quando scriviamo wait_ event intendiamo sia quelli ad attesa esclusiva che non.
Se metto un processo in attesa, chi va in esecuzione? Deve esserci un content switch; devo riuscire a fare un cambio di contesto.
Se arrivasse un interrupt, la routine a un certo punto, invocherà il sottoprogramma wake_up indicando la waitqueue che beneficia dell'arrivo dell'interrupt. Mette quindi processi in attesa in stato di pronto eliminandoli dalla waitqueue. Quindi cancella il descrittore del processo dalla waitqueue e quell'indirizzo va inserito nella runqueue. Se il nuovo task ha maggiore diritto di esecuzione di quello corrente allora è necessario segnalarlo allo schedulare per invocare la preemption. Questo si fa mettendo a uno la variabile globale del kernel TIF_ NEED_ RESCHED. Ricordiamo inoltre inoltre che le periferiche agiscono in maniera asincrona.
Il meccanismo di attesa su una waitqueue e utilizzato molto nei driver e quindi nei gestori di periferica.al verificarsi di un Interrupt, i dati che la periferica deve leggere o scrivere non possono essere trasferiti al processo interessato, che non è quello corrente, ma devono essere conservati nel gestore stesso.
La preemption non viola la regola del kernel non-preemptable ma si applica questa regola: la commutazione di contesto viene svolta durante l'esecuzione di una routine del sistema operativo solo alla fine della routine stessa e se il modo nel quale la routine sta per tornare è il modo utente. Quindi il rescheduling viene fatto prima della IRET o SYSRET. Se un processo chiede la lettura di un dato da tastiera, si mette in attesa della periferica, quindi entra in esecuzione un altro processo. Quando l'Interrupt arriva però e in esecuzione un altro processo.quindi deve arrivare al vecchio processo che adesso è in attesa attesa, quindi il valore da trasferire, viene emesso in un'area di memoria detta buffer della periferica.
IMPLEMENTAZIONE DEI MUTEX
Quando un programma applicativo in modo U esegue un’operazione di lock su un mutex già bloccato il suo processo deve essere posto in stato di ATTESA.
E’ ovvio che per cambiare lo stato del processo bisogna eseguire del codice in modo S, tramite system call.Per evitare questo onere, Linux usa il meccanismo dei futex(FAST USERSPACE MUTEX).
Un mutex è composto da una variabile intera nello spazio U(mutex o semaforo) e da una waitqueue WQ nello spazio S.
Ovviamente se il lock è libero e quindi può essere acquisito non serve mandare in attesa il processo e quindi non serve passare al modo S.Se invece il lock è bloccato è necessaria una system call chiamata sys_futex().Questa possiede:
- un parametro op(operazione richiesta),che può assumere i valori: FUTEX_WAIT o FUTEX_WAKE, in cui la prima serve a porre il processo in attesa, la seconda a risvegliarlo
- L'operazione di Lock di mutex già bloccato si realizza invocando sys_futex(FUTEX_WAIT,…), che invoca wait_ event_ interruptible_ exclusive(WQ) emette quindi il processo in attesa esclusiva sulla waitqueue fino a quando il lock non viene rilasciato
- l’unlock invece si fa con sys_futex(FUTEX_WAKE) risvegliando i processi che sono in waitqueue tramite wakeup(WQ)
Questo è quindi un esempio di attesa eclusiva che risveglia quindi solo uno di tutti i processi presenti in waitqueue. Ricordiamo che schedule() sceglie il prossimo processo da eseguire.
PREEMPTION
La regola base del Kernel abbiamo detto che era quella di non essere preemptive.Data questa regola, non viene eseguita immediatamente una commutazione di contesto quando il sistema scopre che un task che è in esecuzione deve essere sospeso, ma semplicemente, imposta a 1 il flag TIF_NEED_RESCHED, successivamente, al momento opportuno, questo flag causerà la preemption.
La realizzazione della preemption in realtà viola la regola del Kernel appena detta, perchè il SO può decidere di eseguire una preemption solo quando è effettivamente in esecuzione(modo S),quindi evidentemente la preemption deve essere fatta prima del ritorno a modo U. Si applica questa regola:
Vediamo ora alcune funzioni dello scheduler:
- schedule() : già vista, serve a scegliere il processo da mettere in esecuzione.Ha al suo interno:
- if(CURR.stato == ATTESA){dequeue_task(CURR)}, questo si verifica se schedule viene invocata da una funzione wait…
- content switch
- check_preempt_curr(): verifica se il task deve essere preempted( in questo caso TIF_NEED_RESCHED=1)
- enqueue_task() che inserisce un task in runqueue
- dequeue_task() elimina il task dalla runqueue
- resched(): pone TIF_NEED_RESCHED=1, questa operazione viene fatta sempre tramite resched
- task_tick() serve poi a controllare i timeout e ha:
- scheduler periodico, invocato dall’interrupt del clock
- interagisce in modo indiretto con le altre routine del kernel
- determina se il task deve essere preempted perchè scaduto il quanto di tempo(resched())
SERVIZI DI SISTEMA
Iniziamo l’argomento con una curiosità:nel fare una pthread_create() in realtà Linux crea un nuovo processo perchè infatti sappiamo che Linux gestisce solo task.
All’avviamento e quindi al caricamento in memoria del SO, cioè in bootstrap il So deve eseguire operazioni di inizializzazione di alcune strutture dati e nella creazione di un processo iniziale, il processo PID=1, che esegue il programma init.Non ha un padre.
Init crea un processo per ogni terminale sul quale potrebbe essere eseguito un login; questa operazione è eseguita leggendo un certo file di configurazione.Quando un utente si presenta al terminale ed esegue il login, se l’identificazione va a buon fine, il processo che eseguiva il programma di login lancia in esecuzione il programma shell(interprete dei comandi), e da questo momento la situazione è quella di normale funzionamento.
Il nucleo del SO mette a disposizione dei normali processi un insieme di servizi sufficientemente potente da permettere di realizzare molte funzioni generali tramite processi normali.
PROCESSO IDLE
Quando nessun processo è pronto per l’esecuzione, viene messo in esecuzione il processo 1, che dopo l’avviamento, non svolge più alcuna funzione utile, infatti è chiamato IDLE.Ha il diritto di esecuzione inferiore a tutti i processi(infatti deve essere selezionato solo nel caso in cui non ci siano più processi pronti).Inoltre non ha mai bisogno di sospendersi e non è mai in attesa, infatti il suo descrittore non verrà mai aggiunto a nessuna waitqueue.
A livello assembly possiamo pensarlo come una nop eseguita di continuo.Viene inoltre eseguito in modo U.
L’esecuzione di IDLE termina quando c’è un interrupt:
- viene eseguita la routine
- la routine gestisce l’evento dell’interrupt e eventualmente risveglia un processo(wakeup)
- dato che il processo risvegliato ha sempre diritto di esecuzione maggiore di IDLE, TIF_NEED_RESCHED=1
- al ritorno al modo U viene invocato schedule()
SYSTEM CALLS
Le system calls sono usate, come già detto dai processi in modo U per richiedere funzioni del SO.Queste funzioni speciali appartengono alla libreria glibc.
Ogni system call internamente è identificata da una costante simbolica(a cui corrisponde un numero) di tipo sys_xxx con xxx nome della syscall
Come già detto, all’interno della syscall(), funzione C, c’è l’istruzione assembler SYSCALL. syscall deve mettere nel registro rax il numero del servizio richiesto.
La system_call esegue le seguenti operazioni:
- Come in ogni chiamata di funzione, vengono salvati i registri che lo richiedono sullo stack
- controlla che in rax ci sia un numero valido di system call
- invoca il servizio richiesto chiamando una funzione che chiamiamo SYSTEM CALL SERVICE ROUTINE.
- Terminata la routine ricarica i registri dallo stack
- se TIF_NEED_RESCHED == 1 allora invoca schedule()
- ritorna al programma di modo U che lo aveva invocato
CREAZIONE DI TASK
La libreria più usata in Linux a questo scopo è la Native Posix Thread Library(NTPL).pthread_create chiama la sys_call.La pila di un thread va a occupare spazio che è nell’heap del processo padre.Poi all’interno di pthread_create viene invocata la clone(), che vedremo…
I processi normali sono creati con la fork(), mentre quelli leggeri con la thread_create().
Nella glibc c’è una utile funzione che è la clone, che permette di creare un processo con le caratteristiche di condivisione definibili da noi tramite una serie di flag:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...);- il primo parametro è un puntatore a funzione che riceve un puntatore a void come argomento per poi restituire un intero
- il secondo è il puntatore ai parametri da passare alla funzione fn
- child_stack è l’indirizzo dello stack che verrà usato dal processo child
- i flag più importanti sono:
- CLONE_VM che indica che i due processi usano lo stesso spazio di memoria
- CLONE_FILES: condividono la stessa tabella dei file aperti
- CLONE_THREAD: il processo viene creato per implementare un thread; l’effetto è che al nuovo processo viene assegnato lo stesso TGID del chiamante
- La clone() crea un processo che eseguirà la funzione fn.
La thread_create è quindi implementata chiamando la clone, in questo modo:
clone(funz_da_eseguire,stack,CLONE_VM,CLONE_THREAD,argomenti,...)Da notare però che clone non è servizio di sistema, ma il servizio di sistema che crea un processo è sys_clone(), leggermente diverso, ecco il prototipo:
long sys_clone(unsigned long flags, void *child_stack, ... );La clone ha al suo interno syscall.
Vediamo ora l’implementazione di alcune funzioni importanti:
fork(){
...
syscall(sys_clone,0);//0 alla fine indica che non si vuole creare uno stack e che quindi vogliamo fare una fork
...
}
//il valore di SP nel figlio sarà uguale al parent(hanno stesso stack)clone(funz_da_eseguire,stack,CLONE_VM,CLONE_THREAD,argomenti,...)
{
syscall(sys_clone,...);
if(proc_figlio){
funz_da_eseguire(argomenti);
syscall(sys_exit,...)
}
else{
return;
}}Per eliminare i processi ci sono sostanzialmente 2 servizi di sistema:
- sys_exit() che cancella un singolo task
- sys_exit_group() che invece cancella tutti i processi appartenenti ad un certo gruppo
La sys exit è implementata idealmente cosi:
sys_exit(codice){
struct task_struct *task = current()//processo che la esegue, restituito infatti da current()
exit_mm(task);// funzione che rilascia la memoria del task
exit_sem(task);//rimuove il processo dalle code per semafori o mutex
exit_files(tasl);//rilascia i file aperti
wakeup_parent(task->p_pptr) //wake_up del padre
schedule()
}Invece la seconda, per i gruppi viene realizzata inviando un segnale di terminazione a tutti i processi del gruppo per poi eseguire una normale sys_exit.
SCHEDULER
Lo scheduler, prima di fare il content switch e quindi dare disponibilità del processore e delle risorse HW a un altro processo, vede qual’è il processo in stato PRONTO che ha più diritto di essere eseguito e quindi ad usare la CPU.
Come già detto il SO non può essere interrotto per la regola del kernel non preemptable, però si è deciso, violando questa regola, di eseguire il content switch alla fine del codice di un servizio di sistema(prima del ritorno a modo U) e questo accade ovviamente se TIF_NEED_RESCHED == 1.
Ci sono task che hanno maggiore priorità e devono essere eseguiti prima, questa è la regola generale.
Ricordo inoltre che la funzione dello scheduler è quella di decidere quale processo eseguire e se effettuare un content switch.In particolare questo deve garantire che i processi più importanti vengano eseguiti prima dei processi meno importanti e che quelli di pari importanza vengano eseguiti in maniera equa, quindi nessun processo deve attendere il proprio turno per un tempo molto superiore agli altri.
La politica ROUND ROBIN consiste nell’assegnare ad ogni processo uno stesso quanto di tempo o timeslice in ordine circolare.Tutti i processi vengono quindi schedulati per lo stesso stesso tempo a turno.Questa politica è equa e garantisce che nessun processo rimanga bloccato per sempre(starvation).E’ una politica utile specialmente nel caso di task di pari importanza.
Lo scheduler sceglie quindi tra i processi PRONTI uno che ha il maggior diritto di esecuzione.Questo avviene, come sappiamo, quando un processo si autosospende, ogni volta che un processo viene risvegliato(e quindi messo in stato di PRONTO, questa operazione modifica la runqueue e se il processo risvegliato ha maggior diritto di esecuzione di tutti, deve essere eseguito) e per finire, ogni volta che il processo in esecuzione è gestito in Round Robin e il suo timeslice si è esaurito.
CLASSIFICAZIONE DEI TASK
In base alla loro importanza, i task possono essere classificati cosi:
- Processi REAL TIME(in senso stretto): devono soddisfare dei vincoli di tempo molto stringenti e quindi devono essere schedulati con rapidità, garantendo in ogni caso di non superare un determinato vincolo di ritardo massimo.Usati spesso in sistemi di guida autonoma, assistenza alla guida ecc…
- Processi SEMI-REAL-TIME(soft Real Time): questi, pur richiedendo una relativa rapidità di risposta, non richiedono la garanzia assoluta di non superare un certo ritardo massimo.C’è quindi un livello di tolleranza
- Processi NORMALI:tutti gli altri processi, che possono essere CPU BOUND(usano molto la CPU e si sospendono raramente, ad esempio, un compilatore) o I/O BOUND (si sospendono spesso, un editor di testo ad esempio, per aspettare le periferiche)
A livello di codice, ogni politica è implementata da una certa classe di scheduling diversa, a cui corrispondono algoritmi e variabili associate.In C queste sono realizzate con una struct che ha all’interno puntatori a funzioni, in modo da ottenere qualcosa di simile alle classi in C++.
Ogni politica di scheduling è realizzata da una Scheduler Class.Nel descrittore di un processo il campo
constant struct sched_class *sched_classcontiene un puntatore alla struttura della scheduler class che lo gestisce.Lo scheduler è l’unico gestore delle runqueue e per questo le altre funzioni devono chiedere allo scheduler di eseguire operazioni sulla runqueue.
La runqueue viene gestita soltanto dallo Scheduler e quindi ogni altra funzione deve chiedere allo scheduler di eseguire operazioni se vogliono farlo.
Quando viene invocata una funzione dello scheduler, tale funzione svolge poche funzioni preliminari e poi invoca la corrispondente funzione della scheduler class al quale il task appartiene.
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_new = task_new_fair,
};Qui ci sono gli algoritmi associati alla politica fair del Completely Fair Scheduler(CFS).Se una funzione del nucleo invoca enqueue_task, all’interno di questa funzione verrà invocata la funzione corrispondente della sched_class del processo in esecuzione p nel modo seguente:
p->sched_class->enqueue_taskOgni classe di scheduling può a sua volta implementare più di una politica:
- SCHED_FIFO (First In First Out)
- SCHED_RR (Round Robin)
- SCHED_NORMAL
SCHED_FIFO ha diritto di esecuzione maggiore di tutte e 3 le politiche.SCHED_RR tra normal e fifo. SCHED_NORMAL inferiore a tutte.
Quando si invoca schedule(), questa al suo interno invocherà pick_next_task(), che a sua volta invoca le funzioni pick_next_task() specifiche di ogni singola classe in ordine di importanza delle classi.
C’è almeno una politica distinta per ogni classe di scheduling. La priorità con cui viene scelto un processo rispetto a un altro parte dalla priorità delle classi: possiamo avere più processi di categoria FIFO o più task in RR o NORMAL. Se tutti questi sono nella RUNQUEUE o deve essere fatto un cambio di contesto, il processo su cui deve fare switch viene scelto andando a valutare così: i processi FIFO hanno priorità superiore a quelli Round Robin che hanno loro volta priorità maggiore sui NORMAL. All'interno di un insieme di processi di classe FIFO quindi, quello da eseguire viene scelto così: prendo il primo che è stato creato(first in) e quindi il più vecchio della coda.All'interno della della Round Robin, tutti i processi vengono considerati a pari priorità e quindi la scelta del prossimo task da eseguire viene fatta tenendo conto in maniera circolare di qual è stato il diritto di esecuzione di ciascuno. Infine nella normal il processo da eseguire viene scelto in base alle sue caratteristiche. Di seguito l'implementazione della funzione schedule().
schedule(){
...
struct task_struct *prev,*next;
prev = CURR;
if(prev->stato == ATTESA){
dequeue(prev)//il task corrente viene rimosso dalla runqueue rq
}
//oppure se il task corrente è terminato, si fa anche il dequeue
//scelta prossimo task da eseguire
next = pick_next_task(rq,prev);
//se next è diverso da prev esegui il content switch
if(next != prev){
content_switch(prev,next);
CURR->START = NOW;
}
TIF_NEED_RESCHED=0
}invece quella di pick_next_task():
pick_next_task(rq,prev){
for(ogni classe di scheduling){//ordine di importanza decrescente
//invoca una funzione di scelta del prossimo task per la classe in esame
next = class->pick_next_task(rq,prev);
if(next != NULL){
return next;//termina la funzione e restituisce next non appena viene trovato
}
//deve restituire un task PRONTO che ha diritto di esecuzione più alto di tutti
//oppure a prev se non ci sono altri task pronti e il suo stato è diverso da ATTESA
//oppure a IDLE se non si verifica nessuno dei 2 casi enunciati
} Linux non supporta i processi Real Time in senso stretto perchè non è in grado di garantire il non superamento di un ritardo massimo.In queste due classi il concetto fondamentale è quello di priorità statica.Per questi processi sono usate le classi SCHED_FIFO e SCHED_RR.
A ogni processo di queste classi viene attribuita una priorità detta statica perchè è attribuita all’inizio e non varia mai.I valori delle priorità statiche stanno in [1;99].Questa priorità si trova nella task_struct(descrittore processo) come attributo static_prio.
Gli eventuali figli creati da un processo poi ereditano la priorità statica dal parent.L’amministratore di sistema può eventualmente cambiarla.
SCHED_FIFO
Un task di questa categoria viene eseguito senza limiti di tempo(fino ad autosospensione o terminazione) e se ci sono più task, sono schedulati in base alla loro priorità.
SCHED_RR
Qui i task nell’ambito della stessa priorità sono schedultati in Round Robin; pertanto se ci sono diversi tasl in questa categoria allo stesso livello di priorità, ognuno viene eseguito per un certo timeslice.Ci sarà una coda circolare per ogni priorità.
NORMAL
Nei processi normal invece la priorità è dinamica e cambia all’avanzare dell’esecuzione dei vari processi.
I processi NORMAL vengono presi solo se non c’è nessun processo SCHED_FIFO o SCHED_RR in PRONTO.L’attuale scheduler dei processi normali è quello CFS, che funziona in questo modo:
Qui la priorità cambia man mano che avanza il tempo. Se il quanto di tempo si allunga, calano le prestazioni, ma non può essere neanche troppo corto perchè allora significherebbe fare tanti content switch perchè ogni processo esaurirebbe spesso il suo quanto di tempo.C’è quindi questo trade-off.Questa politica si basa sul Round Robin.
Si vedrà come questo scheduler dovrà determinare la giusta durata dei quanti, assegnare un peso ad ogni processo, cosi che ai più importanti sia assegnato più tempo, in modo dinamico, quindi con l’avanzare dell’esecuzione.Infine deve poter risvegliare subito processi che sono stati per lungo tempo in ATTESA, ma senza favorirli troppo.
Due sono le ipotesi fondamentali che facciamo:
- tutti i processi hanno un peso unitario: detto t il processo, t.LOAD=1 per ogni task nella runqueue
- i task non si autosospendono mai e quindi non eseguono wait
I task in questo scheduler vengono tenuti in una coda ordinata detta RB e il funzionamento dello scheduler può essere cosi sintetizzato:
- viene estratto da RB(e reso CURR) il primo task della coda
- CURR viene eseguito fino a che il suo quanto Q assegnato non scade
- CURR viene sospeso e reinserito in RB alla fine della coda
Sia NRT il numero di task presenti nella runqueue a un certo istante:
- viene determinato un periodo PER di schedulazione durante il quale tutti i task devono essere eseguiti
- ad ogni task viene assegnato un quanto di tempo Q = PER/NRT (in ms): a turno ogni task è eseguito per Q millisecondi
DETERMINARE PER DI SCHEDULAZIONE
E’ un numero che ovviamente varia con il variare della quantità di task presenti nella runqueue. Quindi non può essere fissato a priori e bisogna tener conto del trade-off di cui parlavamo all’introduzione del capitolo(il periodo non dovrebbe essere troppo lungo ma neanche troppo corto).
Linux attualmente calcola il PER basandosi su due parametri di controllo(SYSCTL parameter), modificabili dall’amministratore di sistema:
- LT(latenza), di default su Linux 6ms: rappresenta il valore minimo del PER.E’ l’intervallo in cui tutto ciò che è nella runqueue dovrebbe essere andato in esecuzione almeno una volta
- GR(granularità), default 0,75ms: è l’intervallo di tempo minimo per cui un processo prende possesso della CPU
Cosi facendo, il Q assegnato ad ogni processo è
- LT/NRT se NRT•GR<LT
- se NRT•GR > LT(se NRT>8 con i valori di default) il quanto viene allungato in modo che non scenda sotto la granularità
La formula Q=PER/NRT però non tiene conto del LOAD dei task.Allora in Linux si utilizzano altre e due variabili per tener conto del peso di ogni processo:
- RQL(rqload) è la somma di tutti i pesi di ogni task presente in runqueue(inoltre si deve tener conto che ci potrebbe essere una fork o pthread_create)
- LC(load_coeff) è il rapporto tra il peso di un singolo task e il RQL
- il quanto assegnato ad un singolo task è
Se i task avessero peso unitario, la formula diventerebbe Q=PER/NRT (basta sostituire i valori, infatti RQL sarebbe =NRT perchè LOAD=1).
VIRTUAL RUNTIME-VRT
Per mantenere l’ordinamento dei task nella coda RB il CFS usa il concetto di Virtual Runtime(VRT).E’ una misura del tempo di esecuzione consumato da un processo, basato sulla modificazione del tempo reale in base a opportuni coefficienti, cosi che la decisione su quale sia il prossimo task da eseguire possa basarsi soltanto sulla scelta del task a minor VRT.
Dato che RB è ordinata in base ai VRT dei task, il prossimo da mettere in esecuzione sarà il primo di RB e viene indicato con LFT(leftmost), quindi a sinistra troviamo il task a minor VRT.
Considerando un task eseguito per DELTA nsec e che abbandona l’esecuzione, lo scheduler incrementa in quel momento il suo tempo di esecuzione SUM e il suo VRT.
Il suo tempo di esecuzione viene incrementato di DELTA: SUM = SUM + DELTA
L’incremento del VRT avviene con un coefficiente VRTC(vrt_coeff):
La variazione di VRT però non dipende dal peso del processo, ecco perchè:
Q * VRTC = (PER /RQL) * t.LOAD * (1/ t.LOAD) = PER /RQL
Inoltre, per motivi che spiegheremo, lo scheduler mantiene nella runqueue una variabile detta VMIN che è il VRT minimo di tutti i task della runqueue.
- NOW è l’istante corrente
- START è l’istante in cui il processo viene messo in esecuzione
- PREV è il valore di SUM al momento in cui un task viene messo in esecuzione
- DELTA: NOW-START
- si aggiunge una funzione di MAX cosi che alla peggio VMIN assume il valore che aveva prima ma non di meno.Questo perchè VMIN deve crescere in maniera monotona
tick(){
//aggiornamento dei parametri di CURR(proc in esecuzione):
DELTA = NOW - CURR->START;
CURR->SUM = CURR->SUM + DELTA;
CURR->VRT = CURR->VRT + DELTA•CURR.VRTC;
CURR->START = NOW;
//aggiornamento di VMIN della RQ
VMIN = MAX(VMIN,MIN(CURR->VRT,LFT->VRT));
//controllo se è scaduto il quanto
if((CURR->SUM - CURR->PREV) >= Q){
resched();
}
}pick_next_task_fair() sceglie il nuovo task di calsse SCHED_NORMAL e viene invocata solo se le altre classi di scheduling non hanno restituito un task da mettere in esecuzione.Allora viene assegnato a CURR il primo task(LFT) della RB.Se RB è vuota e CURR è terminato o è in wait(quindi non è più in runqueue) lo scheduler mette in esecuzione IDLE.
pick_next_task_fair(rq,previous_task){
if(LFT != NULL){
//RB non è vuoto
CURR = LFT;
//elimina LFT da RB ristrutturando la coda opportunamente
CURR->PREV = CURR->SUM;
}
else{
//il RB è vuoto
if(CURR == NULL){
CURR = IDLE;
//altrimenti CURR non viene modificato
}}
}Gli eventi di wait richiedono inoltre di eseguire sempre un rescheduling, invece se c’è un WAKEUP, si deve decidere se fare un rescheduling, in base a due cose, cioè se il processo appartiene a una classe superiore oppure se il suo VRT è inferiore al VRT del processo corrente.Nel secondo caso si applica una correzione per evitare che un processo che esegue attese brevi causi commutazioni di contesto troppo frequenti.In check_preempt_curr(tw,…), invocata da wakeup(), si ha…
...
if((tw->schedule_class == classe con diritto > NORMAL)||((tw->vrt +WGR*tw->load_coeff)<CURR->vrt)){
resched();
}
...Dove WGR ha un valore di default di 1 ms in Linux.
CANCELLAZIONE E CREAZIONE DI TASK:RICALCOLO PARAMETRI
Sia la cancellazione che la creazione di task comportano il ricalcolo dei parametri della runqueue e dei task perchè cambia il numero di task.
Nel caso della creazione è necessario determinare il VRT iniziale da assegnare al processo e poi valutare la necessità di rescheduling, mentre in caso di EXIT si reschedula sempre.
Memoria
MEMORIA VIRTUALE,PAGINAZIONE
In questa parte si vedrà invece come è gestita la memoria dal SO.Partiamo dal concetto di indirizzi rilocabili:un indirizzo si definisce tale se per ottenere l’indirizzo fisico basta sommare una quantità fissa rispetto allo 0.Vedremo più avanti il significato.
Quando si lancia in esecuzione un programma, la dimensione iniziale è quella determinata dal linker ma poi può variare durante l’esecuzione(ad esempio se il programma fa molte chiamate a funzioni, se cresce l’heap ecc…)
Si usa un modello di memoria lineare, cioè la memoria è costituita da una sequenza di parole o celle che vengono numerate da 0 fino al valore massimo. Ogni cella è identificata da un numero, l’indirizzo.
La nostra memoria la supporremo indirizzata al byte, ogni cella indirizzabile è composta quindi da 8 bit.
- spazio di indirizzamento: numero max di indirizzi possibili(basta guardare la lunghezza dell’indirizzo.Ricorda che se un indirizzo è in esadecimale, per ottenere il numero di bit di cui è composto basta moltiplicare il numero di cifre HEX per 4)
- dimensione:numero di byte di cui la memoria è fisicamente composta.
Alle variabili e le funzioni che definiamo nel codice dei nostri programmi, viene associato un indirizzo che corrisponde poi alla prima cella di memoria che viene allocata dal SO per contenerle.Questi indirizzi sono nella TABELLA GLOBALE DEI SIMBOLI o MAPPA DEL PROGRAMMA(o di sistema se ci si riferisce al SO).
Invece quelle variabili che sono allocate in modo dinamico o sull’heap o sullo stack(var. locali) non hanno un indirizzo associato in modo statico ma il loro indirizzo viene associato al momento dell’allocazione effettiva, durante l’esecuzione, prima possiamo sapere solo la zona nella quale queste verranno allocate.Per questo sono dette variabili anonime.
Quando la CPU esegue un programma, gli indirizzi che contiene l’eseguibile sono detti indirizzi virtuali e il modello della memoria incorporato nel programma è detto memoria virtuale.
Anche per la memoria virtuale(che in genere sarà sempre maggiore o al massimo pari a quella fisica) possiamo parlare di spazio di indirizzamento e dimensione(determinata dal linker, può crescere durante l’esecuzione).
La CPU produce degli indirizzi virtuali, che vengono poi tradotti dalla MMU in un indirizzo fisico.Solo porzioni di memoria virtuale vengono associate a memoria fisica, le porzioni usate dai programmi.Ma cosi facendo, si crea il problema della frammentazione della memoria, per gli spazi vuoti.
Memoria virtuale e fisica non coincidono.Questo problema è risolto dal meccanismo di paginazione.
Nella memoria fisica devono risiedere sia il SO che i programmi.Conviene inoltre tenere in memoria fisica solo una copia di programmi che sono identici in diversi processi.Poi un altro problema da tenere presente è come già detto la frammentazione della memoria.Infine, la dimensione della memoria fisica può essere insufficiente per contenere tutta quella virtuale.
Visto che ogni programma è costruito per funzionare come se il modello fosse quello ideale e quindi come se ogni indirizzo virtuale corrispondesse ad uno fisico, esistono dei meccanismi, che sono trasparenti al programmatore che permettono appunto di creare i programmi secondo il modello della memoria virtuale.
Se ad esempio un programma P fa molte chiamate ricorsive al suo interno e quindi deve aumentare lo stack ma non ha spazio, allora si passa una parte di memoria sul disco fisso.Questo meccanismo è detto paginazione.
IDEA DI BASE DELLA PAGINAZIONE
- La memoria virtuale del programma viene suddivisa in porzioni di lunghezza fissa, che sono le pagine(in Linux la dimensione di default è di 4KB, ma l’amministratore di sistema può modificare il valore)
- la memoria fisica viene suddivisa in pagine fisiche della stessa dimensione delle pagine virtuali
- le pagine virtuali di un programma da eseguire vengono caricate in altrettante pagine fisiche, non necessariamente in aree contigue(non è detto che ogni area dello stesso programma sia vicina, poi vedremo cosa intendiamo per area)
Un indirizzo virtuale del programma viene considerato costituito da un numero di pagina virtuale NPV e da un offset all’interno della pagina.L’indirizzo virtuale poi viene trasformato in uno fisico, costituito anch’esso da un numero di pagina fisica NPF e da un offset nella pagina.
Ricordando la codifica binaria, il fatto di prendere la dimensione della pagina come multipla di 2 è molto utile, perchè cosi le ultime cifre dell’indirizzo rappresentano già l’offset.
Se ad esempio ho una memoria da 1000 indirizzi decimali numerati da 0 a 999 e la suddivido in 10 pagine a lunghezza 100, allora ho bisogno di 1 sola cifra per identificare una pagina(da 0 a 9),più 2 cifre di offset perchè poi mi posso muovere all’interno di una pagina selezionata.Lo stesso vale per il binario. In DEC un esempio di indirizzo può essere 125: pagina 1, offset 25…
Visto che l’offset rimane inalterato nel passare da una pagina virtuale a una fisica, esiste una struttura detta TABELLA DELLE PAGINE(PAGE TABLE-PT) contenuta nel descrittore di un processo.Essa contiene tante righe quante sono le pagine virtuali del programma, ponendo in tali righe i numeri delle pagine fisiche che corrispondono e sostituendo, prima di accedere alla memoria il numero di pagina virtuale con quello fisico.
Esiste ovviamente anche un bit di validità, come per le memorie cache, che se è 0 significa che il contenuto non ha senso o che la pagina si trova sul disco fisso e quindi non è stata trovata in RAM.
Un altro problema da affrontare è la protezione delle pagine, il SO deve far si che un processo non acceda a zone di memoria non consentite, quindi ad esempio alla memoria di un altro processo in esecuzione.
Oltre a questo è necessario controllare anche che un processo operi correttamente sulla memoria alla quale può accedere. Il meccanismo più diffuso a questo scopo consiste nell’associare ad ogni pagina un’informazione che indica se il processo può utilizzarla in lettura(L), scrittura (W) oppure in esecuzione(X).X significa che la pagina contiene codice da eseguire.
Il tipo di diritto di accesso a una pagina può essere inserito nella riga corrispondente della tabella delle pagine e deve essere gestito anche un dall’Hardware, che, in presenza di una violazione di un diritto di accesso deve generare un INTERRUPT DI VIOLAZIONE DELLA MEMORIA.
A volte può succedere che un programma richieda più pagine di quelle fisicamente disponibili.Allora entra in azione la paginazione.
Durante l’esecuzione di un programma solo un certo numero delle sue pagine virtuali è presente in memoria fisica(quindi in RAM/cache) e queste sono dette pagine RESIDENTI.Quando un programma accede ad una pagina, si controlla che l’indirizzo virtuale generato appartenga a una pagina residente, altrimenti si produce un interrupt di segnalazione di errore detto PAGE FAULT e il processo viene sospeso in attesa che la pagina contenente l’indirizzo richiesto venga caricato dal disco in memoria fisica.
Per liberare spazio può accadere anche che una pagina residente venga scaricata sul disco.Una condizione necessaria perchè questo meccanismo funzioni è che il numero di page fault che si verificano sia basso rispetto al numero di accessi.
Come per le cache si utilizzano il principio di località temporale e spaziale(consiglio un ripasso di questi principi spiegati nella parte di Architettura dei Calcolatori).
Per le parti del processo che invece vengono modificate o allocate dinamicamente è necessario che ci sia un file detto SWAP FILE sul quale viene salvata l’immagine delle pagine quando queste vengono scaricate.
Infine, per queste parti, quando una pagina viene scaricata, il SO deve decidere se tale pagina deve essere riscritta sul disco perché è stata modificata oppure no: per permettere questa scelta la MMU(Memory Management Unit) possiede in genere un bit per ogni riga, detto bit di modifica (dirty bit), posto a 0 quando la pagina viene caricata in memoria e posto a 1 quando viene scritta.
In caso di page Fault il SO deve:
- Rintracciare la pagina in memoria
- Trovare memoria centrale centrale spazio per collocarle e quindi scaricare delle pagine
- Caricare la pagina dal disco
- Far rieseguire l'istruzione macchina che ha generato il page Fault
la routine di servizio in caso di page Fault e detta Page Fault Handler, il cui interrupt è sollevato dalla MMU.
if(NPV non appartiene a memoria virtuale del processo)
processo abortito e segnalato SEGMENTATION FAULT
else if(NPV è residente in una pagina fisica PFx, ma viola protezioni){
if(CopyOnWrite) gestisci...
else il processo viene abortito e segnalato un segmentation fault
}
else if(l'accesso è legittimo, ma NPV non è residente in pagina fisica){
if (la NPV è la start address di una VMA che possiede il flag Growsdown) {
aggiungi una nuova pagina virtuale NPV-1 all’area virtuale,
che diventa la nuova start address della VMA;
}
invoca la routine che deve caricare in memoria la pagina virtuale NPV;
}Inoltre l'indirizzo non fanno distinzione tra dati e istruzioni.abbiamo detto che la tabella delle pagine memorizzata e memoria e quindi un accesso a memoria richiede almeno 2 accessi:
- alla tabella delle pagine per ottenere l'indirizzo fisico
- all'indirizzo fisico per il dato
la soluzione è quella di sfruttare il principio di località degli accessi e inserire una cash della tabella delle pagine che tenga traccia delle traduzioni da NPV a NPF utilizzate più di recente: TRANSLATION LOOKASIDE BUFFER(TLB).
Il TLB è composto da un campo etichetta NPV, un campo dati NPF, un bit di validità, dirty(modifica), bit di utilizzo.
Il bit di validità del TLB dice se la corrispondenza NPV NPF è valida.il bit Dirty dice se la pagina fisica è stata modificata.il bit di utilizzo indica che la pagina è stata utilizzata di recente e serve quindi per attuare la politica di sostituzione LRU approssimata.
SPAZIO VIRTUALE DEI PROCESSI
Ad ogni task è associata una tabella delle pagine e ognuno sono associate pagine virtuali che vanno associate a pagine fisiche.il segmentati Fault si ha quando una parte di pagina non è associata al processo e il programma cerca di accedere.
Innanzitutto supporremo disattivo l’ASLR(Address Space Layout Randomization) che rende casuali gli indirizzi del codice e dei dati non fissi come visto in RISC-V(parte Architettura dei Calcolatori).noi lo consideriamo disabilitato ma in genere per motivi di sicurezza in tutti i sistemi operativi è attivato di default.
La memoria virtuale di un processo generalmente non viene considerata come una memoria lineare ma viene suddivisa in porzioni che corrispondono alle diverse parti di un programma durante le esecuzione.
Ci sono tanti stack quanti sono i thread nel processo. La memoria virtuale non è considerata lineare per alcuni motivi, ad esempio che bisogna distinguere diverse parti del programma in base alle caratteristiche di accesso alla memoria, ad esempio in base ai permessi di accesso, perché diverse parti del programma possono crescere separatamente, ad esempio lo stack e i dati dinamici oppure perché ci sono aree di memoria che processi diversi possono condividere, ad esempio quando eseguono lo stesso programma.
La memoria virtuale di un processo Linux È suddivisa in un certo numero di aree di memoria virtuale o VMA (Virtual Memory Area).
Ogni VMA è costituita da un numero intero di pagine virtuali consecutive e che hanno caratteristiche di accesso alla memoria omogenee; quindi un’area virtuale può essere caratterizzata da una coppia di indirizzi virutali che definiscono la fine e l’inizio.
In un processo ci sono 7 diversi tipi di VMA:
- CODICE(C):area che contiene le istruzioni che costituiscono il programma da eseguire
- COSTANTI RILOCAZIONE DINAMICA(K):area destinata a contenere dei parametri determinati in fase di link per il collegamento con librerie dinamiche
- DATI STATICI(S):destinata a contenere i dati inizializzati allocati per tutta la durata del programma(dati globali inizializzati)
- DATI DINAMICI(D):area destinata a contenere i dati allocati dinamicamente su richiesta del programma(ad esempio, in C la memoria allocata tramite la funzione malloc è chiamata heap).Il limite di questa area è indicata dalla variabile brk nel descrittore del processo.Questa area è divisa idealmente in dati non inizializzati ed heap
- PILE DEI THREAD(T):usata per la pila del thread
- AREE PER MEMORY-MAPPED FILES(M): librerie dinamiche e memoria condivisa(tramite la mappatura di un file su aree virtuali di diversi processi
- PILA(P): stack del processo, contiene le variabili locali delle funzioni
Il loader inoltre carica i programmi dal disco alla RAM, esso è infatti una parte di SO.L’area K serve a inizializzare il loader.
I dati non inizializzati sono chiamatati anche BSS(Block Started By Symbol):
- nell’eseguibile tali dati sono statici, che non avendo un valore iniziale, possono essere rappresentati sinteticamente, associando al nome simbolico(etichetta) la quantità di spazio di memoria da usare
- nello spazio virtuale del processo sono considerati come una porzione allocata inizialmente dei dati dinamici e quindi appartengono alla VMA D, non a quella S, perchè il loro comportamento è simile a quello dei dati dinamici
Può capitare che serva una maggiore area di stack, ad esempio quando i programmi usano funzioni ricorsive, matrici dinamiche
In Linux una VMA è definita a livello di codice come una struct chiamata vm_area_struct:
struct vm_area_struct{
struct mm_struct *vm_mm; //la mm_struct del processo alla quale quest'area appartiene
unsigned long vm_start;//indirizzo iniziale dell'area
unsigned long vm_end;//indirizzo finale dell'area
struct vm_area_struct *vm_next,*vm_prev;
unsigned long vm_flags;
//informations about our backing store
unsigned long vm_pgoff; //offset(within vm_file) in PAGE_SIZE units
struct file *vm_file; // file we map to(can be NULL)
...
};
PRINCIPALI VMA FLAGS
#define VM_READ 0x00000001
#define VM_WRITE 0x00000002
#define VM_EXEC 0x00000004
#define VM_SHARED 0x00000008
#define VM_GROWSDOWN 0x00000100
#define VM_DENYWRITE 0x00000800Una VMA può essere mappata su un file, il BACKING STORE oppure può non essere mappata su file e quindi essere presente solo in RAM, allora sarebbe detta ANONYMOUS.
Infatti la struct appena vista contiene anche l’informazione struct file *vm_file, necessaria appunto ad individuare il file usato come backing store e la posizione(offset) all’interno del file stesso(unsigned long vm_pgoff).
Infatti se la VMA è mappata su file allora il puntatore vm_file e vm_pgoff≠NULL nel nodo della VMA.Se invece la VMA è anonima il puntatore è nullo.
struct task_struct{
...
struct mm_struct *mm;//descrittore memoria virtuale del task presente nel descrittore del processo
//memory management
...
}struct mm_struct {
struct vm_area_struct *mmap;
pgd_t *pgd;
//da qui indirizzo dei vari tipi di vma:
unsigned long start_code, end_code;
unsigned long start_data,end_data;
unsigned long start_brk,brk;
unsigned long start_stack;
unsigned long mmap_base;
}Si lascia generalmente una pagina per separare la VMA dello stack, queste pagine sono pagine cuscinetto o di grossdown, possiamo riconoscerle dal fatto che non hanno flag.
Inoltre una VMA può essere creata o dal SO automaticamente quando un processo viene lanciato, oppure con il comando mmap(),che è una system call.
Una VMA può essere mappata su file(quindi su hard disk) oppure anonima e quindi rimane in solo in RAM.
Può essere anche qualificata come SHARED(cioè se una VMA è SHARED tra due processi A e B e A effettua una scrittura/update fatta ad un indirizzo virtuale nella VMA condivisa, questa sarà visibile anche al processo B).Oppure può essere PRIVATE(in caso di scrittura/update, questa rimane visibile solo al processo a cui la VMA appartiene).
Quindi, la classificazione delle VMA è questa:
- VMA SHARED MAPPATA SU FILE
- VMA PRIVATE MAPPATA SU FILE
- VMA SHARED ANONIMA(usate per la comunicazione tra processi)
- VMA PRIVATE ANONIMA
Come già detto, ogni volta che la Memory Management Unit(MMU) genera un interrupt di Page Fault su un indirizzo virtuale appartenente ad una pagina virtuale NPV, viene attivata una routine detta PAGE FAULT HANDLER(PFH).Nel capitolo precedente abbiamo visto l’algoritmo per la gestione del Page Fault.
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);Dove:
- addr: indirizzo virtuale da cui deve iniziare la VMA(o meglio, dove dovrebbe, perchè non è garantito che cominci esattamente da quell’indirizzo preciso, il sistema cerca di avvicinarlo il più possibile
- length: è la dimensione dell’area in byte
- prot indica la protezione, può essere PROT_EXEC, PROT_READ, PROT_WRITE
- flags: ne sono tanti, ma consideriamo MAP_SHARED, MAP_PRIVATE e MAP_ANONYMOUS
- fd è il descrittore del file da mappare
- offset indica la posizione iniziale dell’area rispetto al file(numero di byte rispetto all’inizio del file)
Creare una VMA in realtà non significa occupare memoria fisica, ma agire su strutture del SO.Si deve poi aggiornare la tabella delle pagine.All’atto di creazione, non c’è paginazione, ma c’è il DEMAND PAGING.
Un altro concetto fondamentale è l’entry point, che è l’NPV che indica l’istruzione iniziale del programma(contenuta in main).
Riassumendo, al momento dell’exec la VMA di pila viene creata con un certo numero di pagine iniziali, non allocate fisicamente eccetto quelle utilizzate subito.Ogni accesso a NPV non allocate fisicamente ne causa l’allocazione.Il tentativo di accedere pagine diverse da quelle esistenti o quella di grossdown produce un segmentation fault.
Durante una fork, dato che il nuovo processo è immagine del padre, Linux si limita ad aggiornare solo le informazioni della tabella dei processi, non alloca nuova memoria.Linux opera come se il nuovo processo condividesse tutta la memoria con il padre.
Linux opera come se il nuovo processo condividesse tutta la memoria con il padre.Questo vale finchè uno dei due processi non scrive in memoria, allora in quel caso, la pagina scritta viene duplicata perchè i due processi poi hanno dati diversi in quella stessa pagina.Questo meccanismo è detto COPY ON WRITE(COW).
Ovviamente in questo modo si evita di andare a duplicare inutilmente quelle pagine che rimangono invariate.L’idea del COW è la seguente:
- quando si viene a creare la situazione di condivisione, le pagine vengono abilitate in sola lettura(R) alle pagine condivise, anche quelle appartenenti ad aree virtuali scrivibili di ambedue i processi
- quando si verifica un page fault per violazione di protezione in scrittura, il Page Fault Handler(PFH) verifica se la pagina protetta R appartiene a una VMA scrivibile e in tal caso, se necessario la duplica e cambia la protezione in W, rendendo la scrittura possibile
Quindi se supponiamo che due processi A e B condividano una stessa pagina fisica, quindi un file che chiamiamo F1 e A ha associata la pagina virtuale V1 e B V2. F1 è in protezione R e se il processo A tenta di scrivere in V1, quello che accade, in base a quanto detto è che si verifica un page fault, viene duplicato il file F1 creandone uno F2 con diritto W.A questo punto, F2 viene associato alla pagina V1, cosi che la scrittura può avvenire.Adesso, F1 non è più condiviso quindi se anche il processo B deve effettuare una scrittura sulla pagina virtuale V2 può farlo direttamente cambiando la protezione di F1 da R a W, proprio perchè ora F1 non è più condiviso.
Per permettere al Page Fault Handler di sapere se una pagina richiede duplicazione o no ad ogni pagina fisica, è attribuito in una apposita struttura dati detta descrittore di pagina(PAGE DESCRIPTOR) un contatore ref_count che indica il numero di utilizzatori della pagina fisica.
- se la pagina fisica è libera, ref_count restituisce 0
- se la pagina fisica ha N utilizzatori, ref_count restituisce N
Quindi si può modificare l’algoritmo del PFH cosi:
if (NPV non appartiene alla memoria virtuale del processo)
il processo viene abortito e viene segnalato un “Segmentation Fault”;
else if (NPV è allocata in pagina PFx, ma l’accesso non è legittimo perché viola le protezioni) {
if(VIOLAZIONE CAUSATA DA ACCESSO IN SCRITTURA A PAGINA PROTETTA R DI UNA VMA
A PROTEZIONE W){
if([ref_count di pagina fisica che ha causato fault]>1){
copia il file in una nuova pagina fisica
poni ref_count di questa a 1
decrementa il ref_count della prima pagina(che ha causato il fault)
assegna NPV alla nuova pagina fisica e scrivi in quest'ultima
}
}
else{
abilita NPV in scrittura
}
}
else if(accesso leggittimo ma NPV non è allocata in memoria){
if(NPV è lo start address di una VMA con flag GROSSDWON){
aggiungi una nuova pagina virtuale NPV-1 all'area virtuale,
questa diventa il nuovo start address della VMA
}
routine che carica in memoria la pagina virtuale NPV
}Quando viene fatta una fork, Linux associa la pagina fisica originale al processo figlio e crea una nuova copia per il padre.
Cosa succede quando viene creato un Thread?
Semplicemente, sappiamo che i thread condividono tutte le VMA con il processo che li genera, tranne per lo stack. Infatti ci ricordiamo che tra i tipi di VMA associate ad un processo c’è proprio la VMA per i thread, cioè quella di tipo T, riservata per tutti gli stack di ogni thread. Ogni thread può avere uno stack da massimo 8mb(2048 pagine).
Per separare una VMA T dalle altre Linux inserisce delle aree di interposizione , cioè singole pagine con protezione R.Non mette il flag di Grossdown perchè non può crescere ulteriormente, max 8 mb.
Si nota che le aree di interposizione permettono una protezione molto debole rispetto allo sconfinamento di pila di un thread.
Esiste anche una funzione per eliminare il mapping di un certo intervallo di pagine virtuali:
int munmap(void *addr, size_t length);Il meccanismo che permette di evitare che un processo rilegga dal disco fisso una pagina già caricata in memoria è basato su una struttura dati detta PAGE CACHE.E’ un insieme di pagine fisiche utilizzate per rappresentare i file in memoria e un insieme di dati e funzioni che ne gestiscono il funzionamento.
Ogni descrittore di pagina ha un identificatore del file e un offset sul quale la pagina è mappata e informazioni come il ref_count di cui abbiamo parlato prima.Inoltre c’è una struttura detta PAGE_CACHE_INDEX per la ricerca di una pagina in base al suo descrittore costituito dalla coppia <Identificatore File, Offset>.
Quando un processo richiede di accedere a una pagina virtuale che è mappata su file, il SO…
- determina il file e il page offset richiesto; il file è indicato nella VMA e l’offset è somma dell’offset della VMA rispetto al File sommato all’offset dell’indirizzo di pagina richiesto rispetto all’inizio della VMA
- verifica se la pagina esiste già nella Page Cache; in caso positivo la pagina virtuale viene semplicemente mappata su questa pagina fisica.Altrimenti alloca una pagina fisica nella page cache e carica la pagina del file cercata
Se i campi file e offset del descrittore della VMA sono non nulli allora la VMA è mappata su file.
SCRITTURA SU AREA SHARED
I dati vengono scritti sulla pagina della Page Cache, condivisa:
- la pagina fisica viene modificata e marcata dirty
- tutti i processi che mappano tale pagina fisica vedono immediatamente le modifiche
- prima o poi la pagina modificata verrà riscritta sul file
SCRITTURA SU AREA PRIVATE
Qui entra in gioco il meccanismo del COW già descritto:
- le pagine delle VMA in protezione W vengono portate a R
- quando un processo scrive su una di queste pagine, si verifica un Page Fault per violazione di protezione
- Il page fault handler procede cosi:
- alloca una nuova pagina in memoria fisica
- copia in questa nuova pagina il contenuto della pagina che ha generato il Page Fault
- pone nella PTE relativa a NPV l’indirizzo fisico della nuova pagina e modifica il diritto di accesso a W
- il processo riparte e scrive all’indirizzo NPV, quindi nella nuova pagina fisica associata
Linux cerca di tenere in RAM le pagine lette da disco il più a lungo possibile, in modo da evitare nuovi accessi a disco che sono dispendiosi in termini di prestazioni.
SCRITTURA SU ANONYMOUS
Il SO usa queste aree per la pila o l’area dei dati dinamici dei processi.Le pagine virtuali di questo tipo sono tutte mappate sulla ZeroPage, cioè una pagina fisica piena di zeri mantenuta dal SO.La scrittura in una pagina provoca l’esecuzione del COW, e richiede l’allocazione di nuove pagine fisiche.
Dato che non hanno un backing store utilizzabile le pagine anonime devono essere salvate su un file dedicato allo scopo, detto SWAP FILE.Il SO non finisce mai in SWAP.
Inoltre il SO cerca di mantenere ciò che viene letto da disco in un’area detta DISK CACHE(BUFFER).
GESTIONE MEMORIA FISICA
In questa parte si vedrà la relazione che c’è tra RAM e disco fisso.
L’allocazione della memoria può essere così suddivisa:
- ALLOCAZIONE A GRANA GROSSA:associa ai processi grandi porzioni di memoria sulle quali operare
- ALLOCAZIONE A GRANA FINE:alloca le strutture dati piccole nelle porzioni a grana grossa
Ci occupiamo del primo tipo, la cui unità di allocazione è la pagina o un gruppo contiguo di pagine.
La chiamata di sistema in C brk() serve ad aumentare la dimensione del segmento dati dinamici(D).Questa è un’operazione a grana grossa.Questa funzione incrementa lo spazio virtuale ma non alloca memoria fisica.Solo quando il processo va a scrivere nello spazio virtuale la memoria fisica necessaria viene allocata.
Il termine swapping si riferisce allo scaricamento di un intero processo, paging a quello di una singola pagina.Linux in realtà implementa soltanto il paging, ma nel codice e nella documentazione di Linux si usa il termine swapping.
Le aree di memoria che contengono blocchi letti da disco sono chiamati buffer di solito, ma in Linux questi vengono chiamati DISK CACHE, in quanto memoria di transito dal disco.Queste ovviamente non sono delle cache hardware come quelle che ci sono tra RAM e CPU.
La più importante disk cache è la Page Cache.
Quando la RAM viene occupata e supera un certo livello critico, il sistema può intervenire per ridurre il numero di pagine occupate(PAGE RECLAIMING).
La riscrittura su disco di una pagina in RAM dipende dal suo dirty bit, se questo è asserito e quindi sono state fatte modifiche sulla pagina, allora prima di liberarla dalla RAM deve essere riscritta sul disco.
La DEALLOCAZIONE avviene in questo modo:
- le pagine di page cache non più utilizzate dai processi(ref_count = 1) vengono scaricate; se questo non è sufficiente
- alcune pagine usate dai processi vengono scaricate
- se lo spazio del punto 2 non è sufficiente, un processo viene eliminato completamente(killed).C’è un processo DEAMON che uccide i processi
Il SO deve ovviamente intervenire prima che la riduzione di RAM disponibile scenda sotto una soglia minima che manderebbe in blocco il sistema e renderebbe impossibile qualsiasi intervento.
Si può vedere questo, con il comando free che restituisce una tabella cosi fatta:
- colonna total: quantità di memoria fisica disponibile
- used: quantità di memoria usata
- free: quantità di memoria libera e ancora utilizzabile(used+free=total)
- shared non è più usato
- buffers e cached è la quantità di memoria usata per i buffer o le cache
La quantità di memoria libera può scendere sotto un livello critico detto minFree.Al di sotto interviene il PFRA(algoritmo che vedremo) per liberare le pagine, fino ad avere maxFree pagine libere, un livello ottimale.
SWAP OUT: pagine liberate dalla RAM e portate sul disco.PFRA deve decidere quante e quali pagine si devono liberare e cercherà di raggiungere maxFree.
L’algoritmo PFRA interviene quando:
- (freePages-requiredPages)<minFree
- freePages<maxFree →attivazione di una funzione periodica tramite kswapd(KERNEL SWAP DAEMON)
il primo caso si ha se un task chiede un certo numero di pagine.Esistono 2 liste globali ordinate relativamente all’accesso che sono dette LRU LIST e collegano tutte le pagine virtuali che appartengono ai vari processi:
- ACTIVE LIST: contiene tutte le pagine che sono state accedute recentemente e non possono essere scaricate(ordinate da sinistra a destra, youngest → oldest) in modo che il PFRA non deve scorrerle per prendere una pagina da scaricare
- INACTIVE LIST:contiene tute le pagine inattive da molto tempo(ordinate da sinistra a destra, youngest → oldest) che sono candidate per essere scaricate.
Quando un programma richiede memoria in maniera inarrestabile(supponiamo di avere swap disabilitato), interviene una funzione di Linux detta OOMK(OUT OF MEMORY KILLER).
L’allocazione può avvenire anche a blocchi di pagine, cosi da tenere la memoria il meno frammentata possibile.Ecco i principi di base per l’allocazione a blocchi:
- la memoria è suddivisa in blocchi di pagine contigue, la cui dimensione è sempre potenza di 2(ORDINE DEL BLOCCO).Una costante, detta MAX_ORDER definisce la dimensione massima dei blocchi
- per ogni ordine esiste una lista che collega tutti i blocchi di quell’ordine
- le richieste di allocazione indicano l’ordine del blocco che desiderano
- se un blocco dell’ordine richiesto è disponibile viene allocato, se non lo è un blocco doppio viene diviso in 2 una volta
- I due nuovi blocchi sono detti buddies (compagni) l’uno dell’altro; uno viene allocato e un altro viene lasciato libero.
- Se serve, la suddivisione procede ricorsivamente
- Quando un blocco viene liberato il suo buddy viene analizzato e se è libero i due vengono unificati ricreando un blocco più ampio
Linux non effettua controlli sulla RAM quando un grande quantitativo è libero.Però la memoria richiesta dai processi e dalle disk cache cresce in continuazione:
- quella allocata per i processi viene liberata non appena il processo termina.Questa può crescere o decrescere, in base al numero di processi in esecuzione e in base alle pagine richieste da ogni processo.
- quella destinata invece alle disk cache cresce continuamente perchè non c’è un criterio per sapere se un certo dato letto dal disco ci servirà sicuramente o no
Quindi come già detto quando la memoria residua scende sotto un certo livello critico, interviene un algoritmo che libera delle pagine, il PFRA(Page Frame Reclaiming Algorithm, basato su meccanismo LRU, Least Recently Used).Siccome anche il PFRA richiede un minimo di memoria per funzionare, si deve far in modo che questo intervenga prima che la memoria scenda sotto quel livello critico che bloccherebbe il sistema.
Il livello ottimale di pagine libere, come già detto è maxFree. Ci sono quindi questi problemi da affrontare:
- Quando e Quante pagine liberare
- Quali pagine liberare: ci serve quindi un’informazione su quanti accessi vengono fatti e poter fare la scelta delle pagine meno utilizzate
- lo swapping, cioè l’effettivo scaricamento delle pagine con liberazione della memoria(swapout) e eventuale ricaricamento delle pagine swappate in memoria(swapin)
1-QUANDO E QUANTE PAGINE LIBERARE?
Per affrontare il primo problema c’è bisogno delle seguenti variabili:
- freePages: numero di pagine di memoria fisica libere in un certo istante
- requiredPages: numero di pagine richieste da un certo task o dal SO
- minFree: numero minimo di pagine libere sotto il quale non si vuole scendere
- maxFree: numero di pagine libere ottimale
- toFree: pagine da liberare effettivamente, con l’obbiettivo di avvicinarsi a maxFree
Quindi il PFRA cerca di far avvicinare freePages a maxFree.Abbiamo già parlato dei casi in cui il PFRA viene invocato.
2-QUALI PAGINE LIBERARE?
Per il PFRA i tipi di pagine sono:
- pagine non scaricabili: pagine statiche del SO dichiarate non scaricabili, pagine allocate dinamicamente dal SO, pagine appartenenti alla sPila dei task
- pagine mappate sul file eseguibile dei processi che possono essere scaricate senza mai riscriverle(codici o costanti)
- Pagine che richiedono una Swap Area su disco fisso per essere scaricate quindi da RAM a disco: pagine dati, pagine della uPila, pagine dello Heap
- Pagine mappate su file: ad esempio per buffer o cache
3-MANTENIMENTO INFORMAZIONE RELATIVA ALL’ACCESSO ALLE PAGINE
Come già detto ci sono due liste, la active e la inactive che servono a tener traccia delle pagine accedute dai processi.In queste liste le pagine sono tenute in ordine di invecchiamento, spostando pagine da una lista all’altra per tener conto degli accessi in memoria.
L’obbiettivo dello spostamento è quello di accumulare le pagine meno utilizzate in coda alla inactive, mantenendo nella active le pagine più usate di recente(WORKING SET) di tutti i processi.
Per tener traccia del numero di accessi, Linux utilizza un bit di accesso A presente nel TLB, che viene posto a 1 dal x64 ogni volta che la pagina viene acceduta e può essere azzerato dal SO.
Vediamo una semplificazione del PFRA.
Ad ogni pagina viene associato un flag chiamato ref(referenced), oltre al bit di accesso A impostato dall’HW.Serve a raddoppiare il numero di accessi necessari per spostare una pagina da una lista all’altra.
Definiamo una funzione, Controlla_Liste, attivata periodicamente da kswapd, una funzione semplificata rispetto alla realtà:
- SCANSIONE DELLA ACTIVE DELLA CODA spostando eventualmente alcune pagine alla inactive
- SCANSIONE DELLA INACTIVE DALLA TESTA: escluse le pagine appena inserite provenienti dalla active, spostando eventualmente alcune pagine alla active
SCANSIONE ACTIVE LIST DA SX <- DX
SE A e ref CONCORDI
SPOSTA P in TESTA(ACTIVE se A==1, INACTIVE se A==0)
ref:=1
SE A e ref DISCORDI
ref:=A
SE A==1{ A:=0 }SCANSIONE INACTIVE LIST DA SX->DX
SE A e ref CONCORDI
SPOSTA P in CODA(active se A==1, inactive se A==0)
ref:=0
SE A e ref DISCORDI
ref:=A
SE A==1
A:=0Parliamo infine di swapping.
Questo meccanismo richiede che sia definita almeno una SWAP AREA sul disco.Supponiamo per adesso che ci sia un file destinato a questo semplicemente, uno swap file.
La struttura di ogni Swap Area è descritta da un descrittore, che contiene un contatore per ogni Page Slot, detto swap_map_counter; tale contatore verrà utilizzato per tener traccia del numero di PTE che riferiscono la pagina fisica swappata
REGOLE SWAPPING:
- quando PFRA chiede di scaricare una pagina (SWAP OUT):
- viene allocato un Page Slot
- la pagina fisica viene copiata nel Page Slot e liberata
- allo swap_map_counter viene assegnato il numero di pagine virtuali che condividono la pagina fisica
- in ogni PTE che condivide la pagina fisica viene registrato il SWPN del Page Slot al posto del NPF e il bit di presenza viene azzerato
- quando un processo accede a una pagina virtuale swappata:
- page fault
- caricamento della pagina da disco (SWAP IN), quindi viene allocata una pagina in memoria
- il Page Slot indicato dalla PTE viene copiato nella pagina fisica
- la PTE viene aggiornata inserendo il NPF della pagina fisica al posto del SWPN del Page Slot
SWAP OUT
Una volta trovate le pagine da liberare, lo swap out è semplice da realizzare.Per ogni pagina che deve essere liberata, si tratta solo di determinare:
- se la pagina è dirty, in tal caso il suo contenuto deve essere salvato su disco
- se la pagina è mappata su file in maniera shared oppure è anonima; se è mappata su file deve essere scritta su tale file; se è anonima deve essere salvata nella swap area
SWAP IN
Se la pagina non è stata mai modificata dal momento dello swap in, Linux evita di doverla riscrivere su disco ovviamente.Questo grazie alla Swap Cache, un meccanismo simile alla Page Cache.
Infatti quando una pagina viene swappata, la Swap Area costituisce per tale pagina una specie di backing store; la situazione è simile a quella di una VMA mappata su file, ma vale per ogni singola pagina e non per aree.
Dato che le pagine che richiedono lo swapping sono quelle anonime e non prendiamo in considerazione le anonime shared(per la IPC-InterProcess Communication) consideriamo solo quelle private.
- quando si esegue uno swap in la pagina viene copiata nella memoria fisica ma la copia nella Swap Area non viene eliminata; la pagina letta viene marcata in sola lettura
- nel Swap_Cache_Index viene inserito un descrittore che contiene i riferimenti sia alla pagina fisica che al page slot
- finchè la pagina viene solo letta, questa situazione non cambia e se la pagina viene nuovamente scaricata non è necessario riscriverla su disco
- se la pagina viene scritta, c’è un page fault:
- la pagina diventa privata, non appartiene più alla swap area
- protezione cambiata a W
- swap_map_counter viene decrementato
- se il contatore è 0 il Page Slot viene liberato nella Swap Area
Per quanto riguarda le liste LRU il comportamento è il seguente:
- la NPV che è stata letta o scritta, cioè quella che ha causato lo Swap_in viene inserita in testa alla coda active e con ref=1
- se ci sono altre NPV condivise all’interno della stessa pagina vengono poste in coda alla inactive con ref=0
Si possono verificare inoltre problemi come il TRASHING, cioè il SO continua a deallocare pagine richieste dai processi e vengono continuamente scritte e rilette dal disco e nessun processo riesce ad andare avanti.
TABELLA DELLE PAGINE
In questa parte ci occupiamo di come è fatta la MMU del processore x64 e di come il SO può accedere e usare indirizzi fisici, come esso gestisce la memoria fisica, senza dover passare dalla MMU.
Ricordiamo che tra le cose da ricordare c’è il TLB che permette di realizzare ciò, che è come una cache delle pagine usate più di recente e la tabella delle pagine che contiene appunto la corrispondenza NPV-NPF.
La soluzione è una soluzione HW, che dipende dal processore, per noi è il processore x64.
Il Kernel ha indirizzi che partono da FFFF 8000 0000 0000 a FFFF FFFF FFFF FFFF, cioè ha massimo 2^47 byte, ossia 128 Terabyte di spazio virtuale.
Vediamo adesso come questo spazio è suddiviso internamente:
- codice e dati del SO occupano solo 512 Mb
- per i moduli a caricamento dinamico ci sono 1.5 Gb
- metà spazio virtuale del SO(cioè 2^46 byte → 64 Tb) viene riservato alla mappatura della memoria fisica, quindi per permettere al Kernel di accedere a indirizzi fisici
- una vasta porzione viene riservata poi per le strutture dinamiche del Kernel
- altro
| AREA | COSTANTI INDIRIZZI INIZIALI | DIMENSIONE | INDIRIZZO INIZIALE |
| MAPPATURA MEMORIA FISICA | PAGE_OFFSET | 64Tb | FFFF 8800 0000 0000 |
| MEMORIA DINAMICA KERNEL | VMALLOC_START | 32Tb | FFFF C900 0000 0000 |
| MAPPATURA MEMORIA VIRTUALE | VMEMMAO_START | 1Tb | FFFF EA00 0000 0000 |
| CODICE E DATI | _START_KERNEL_MAP | 0.5Gb | FFFF FFFF 8000 0000 |
| AREA MODULI DINAMICI | MODULES_VADDR | 1.5Gb | FFFF FFFF A000 0000 |
Si possono trovare questi indirizzi e dimensioni nel file Linux/arch/x86/include/asm/page_64_types.h .
PAGE_OFFSET-Accesso agli indirizzi fisici da parte del sistema operativo
Il SO deve essere in grado di accedere agli indirizzi fisici, anche se, come tutto il resto del software opera su indirizzi virtuali.Nella TP(tabella delle pagine) ovviamente gli indirizzi sono fisici perchè devono essere utilizzati direttamente dall’HW.
Per operare sulla TP il SO deve essere in grado di accedere alla memoria anche tramite indirizzi fisici.Per risolvere questo problema, si dedica una parte della memoria virtuale alla mappatura della memoria fisica.L’indirizzo di questa area è definito dalla costante PAGE_OFFSET corrispondente all’indirizzo fisico 0.
In altre parole, si riservano 64Tb per fare un mapping 1:1 della memoria.L’indirizzo iniziale è quindi PAGE_OFFSET.
MEMORY MANAGEMENT UNIT-MMU
La MMU è l’unità che gestisce la memoria a livello HW.La MMU può essere un componente interno alla CPU o esterno.
Un indirizzo virtuale fa riferimento a uno spazio virtuale di 2^48 byte. La paginazione ha pagine da 4Kb.La struttura dell’indirizzo(da 48 bit) in x64 si decompone in:
- 36 bit di NPV(2^36 pagine virtuali) per individuare la pagina
- 12 bit di offset nella pagina(perchè ogni pagina è da 4Kb)
Siccome il numero di pagine virtuali è molto grande, non conviene allocare una TP per ogni processo.
Ci sono funzioni del SO che convertono un indirizzo virtuale in fisico.
Allora la TP è organizzata come un albero a 4 livelli:
- 36 bit del NPV sono divisi in 4 gruppi da 9 bit perchè altrimenti dovremmo allocare una tabella fatta da 2^36 righe.
- ogni gruppo da 9 bit rappresenta l’offset all’interno di una tabella(DIRECTORY) contenente 512 righe(chiamiamo PTE-Page Table Entry le righe di queste tabelle)
- Dato che ogni PTE occupa 64 bit(8 byte), la dimensione di ogni directory è di 4 Kb, cioè ogni directory occupa una pagina
- l’indirizzo della directory principale è contenuto in CR3
Quindi, prendo i 36 bit di NPV, li divido in 4 gruppi da 9.Però l’indirizzo che riceviamo è da 64 bit(da 48 al 63 sono inutilizzati).Ogni gruppo rappresenta l’offset in una tabella, che è fatta quindi da 512 righe(2^9).Ogni riga ha al suo interno 64 bit, perchè corrisponde a un indirizzo fisico.Spieghiamo meglio, vedendo cosa accade ogni volta che il processore usa un indirizzo…
Ad ogni processo viene associata una tabella iniziale da 512 righe.L’indirizzo contenuto nel registro CR3 è proprio l’indirizzo di questa prima tabella.Da qui ottengo un indirizzo a 64 bit della tabella successiva.Quindi i 9 bit successivi dell’indirizzo principale, vanno a individuare un’altra riga.Questa seconda tabella conterrà un indirizzo da 64 bit che rappresenta l’indirizzo di partenza della tabella successiva, fino ad arrivare alla quarta tabella che mi da finalmente il valore dell’indirizzo fisico.
Si attraversano quindi 4 tabelle: la prima la chiamiamo PGD(Page Global Directory), la seconda PUD(Page Upper Directory), la terza PMD(Page Middle Directory) e la quarta è la Tabella delle Pagine(PT).
Da qui viene fuori l’utilità del TLB: risparmia 4 accessi…
Il meccanismo di conversione di un NPV in NPF si basa sui seguenti passi:
- accedi alla directory di primo livello tramite registro CR3
- trova la PTE indicata dall’offset di primo livello di NPV
- leggi a questo offset l’indirizzo base della directory di livello inferiore
- ripeti per i livelli inferiori
I 12 bit meno significativi negli indirizzi intermedi(nell’indirizzo da 48, ma nelle tabelle intermedie che abbiamo detto), sono usati per indicare dei flag invece che un offset(perchè durante le tabelle intermedie, ancora non ci serve individuare un byte nella pagina).Per curiosità vediamo quali sono:
- BIT 0: P-Present, PTE ha un contenuto valido
- BIT 1: R/W(1 pagina W 0 read only)
- BIT 2: la pagina appartiene a spazio S(0) o U(1)
- BIT 5: A-Accessed, la pagina è stata acceduta
- BIT 6: D-Dirty, la pagina è stata modificata
- BIT 8:G-Global Page
- BIT 63: NX-No execute, usato per indicare se la pagina è eseguibile
Quindi all’inizio, si devo attraversare tutte e 4 le tabelle per trovare un indirizzo fisico, ma poi, una volta creata la corrispondenza, questa viene inserita nel TLB.L’attraversamento di tutte le tabelle è detto PAGE WALK(5 accessi a memoria per trovare una sola cella di memoria).
Quando si fa un content switch nel CR3 si carica l’indirizzo della prima pagina della TP del processo(quella globale associata al processo).Quindi a questo punto la MMU invalida tute le PTE che sono nel TLB tranne quelle con il flag G(globali, ossia quelle del SO, condivise da più processi, sono ad esempio le funzioni di sistema ecc, queste non serve rimuoverle).
La MMU cerca in modo autonomo nella TP le PTE di pagine non presenti e quando viene richiesto un indirizzo virtuale, la MMU verifica se la pagina X richiesta è presente nel TLB.Se P è presente, la accede, altrimenti si verifica un TLB MISS.
In questo caso, la MMU deve:
- eseguire il PAGE WALK per recuperare la PTE relativa a P
- se questa è valida il contenuto della PTE viene copiato nel TLB e la pagina viene acceduta
- se questa non è valida c’è un page fault(si deve recuperare la pagina dal disco)
MMU e TLB sono gestiti dall’HW.
Tutte le PGD(Page Global Directory) sono divise in due metà, 256 righe per la parte U e 256 per la S.
FILESYSTEM
E’ l’intera struttura delle directory del disco.Ci sono più di 100 filesystem diversi che possiamo utilizzare.Noi vedremo come Linux li gestisce.
Il Filesystem è quel componente di SO che realizza i servizi di gestione dei file, che consente tramite le chiamate di sistema di andare a effettuare determinate operazioni sui file.
Il SO ha una rappresentazione dei file su disco che è fatta per livelli.Ha un insieme di funzioni del SO che danno l’opportunità alle applicazioni alle applicazioni di utilizzare il filesystem, senza preoccuparsi delle operazioni necessarie per andare a recuperare sul dispositivo le informazioni.
Per questo vine definito un VIRTUAL FILE SYSTEM che è quello visto dagli applicativi e poi in base al tipo di filesystem avrà le operazioni specifiche che vengono attuate su file da quel filesystem e su quell’harware.
Le astrazioni usate sono relative a come è rappresentato un file, che è una sequenza di byte, che abbiamo visto essere suddiviso in pagine, direttori e file speciali(le directory sono dei file con attributi particolari), ogni file ha attributi e politiche di accesso(scrivibile, eseguibile o leggibile) e mapping del file sul dispositivo fisico.
Un VOLUME è il dispositivo di memorizzazione non volatile.Può essere diviso in parti, dette PARTIZIONI che possono avere un diverso tipo di filesystem.
Ogni partizione risulta essere un dispositivo logico indipendente, ad esempio se partiziono il disco è come se creassi un insieme di dischi su cui posso montare SO diversi sulle varie partizioni oppure posso avere un unico SO che gestisce con filesystem diversi più partizioni.
L’indirizzamento dei dati si basa però sul concetto di blocco, quindi l’intero volume o partizione è divisa in blocco, in cui ogni blocco ha un suo indirizzo, detto LOGICAL BLOCK ADDRESS(LBA).
Posso vedere l’intero volume come suddiviso in un array di blocchi.
Il blocco è quindi l’unità fondamentale, trasferita in una sola operazione tra disco e memoria centrale tramite DMA.
Quindi se ad esempio richiedo un carattere da un file sul disco, quello che succede è che viene trasferito l’intero blocco, o meglio, se il carattere si trova in blocchi da 1024 e sappiamo che una pagina è 4Kb, viene trasferita l’intera pagina, quindi 4 blocchi.
L’accesso ai file su disco/periferiche rappresenta l’operazione più lenta che si fa.Infatti Linux utilizza la Page Cache proprio per tenere in memoria centrale i dati letti il più a lungo possibile.
Quindi, quando si richiede un pezzo di file ad esempio, dal VFS(Virtual File System) si va a controllare se per caso era già presente sulla Page Cache, in modo da non dover rileggere da disco.
Un file è costituito da:
- una sequenza di byte
- un nome simbolico e univoco nel direttorio
- un insieme di attributi(tipo, locazione nel dispositivo, dimensione, protezione, time stamp, proprietario)
Un file in Linux può:
- contenere dei dati o programmi se si tratta di un file normale
- contenere riferimenti ad altri file se si tratta di un direttorio
- rappresentare l’astrazione di un dispositivo periferico(file speciale)
Tutte le operazioni sul contenuto del file richiedono il trasferimento in/da memoria di byte e partono dalla posizione corrente nel file, aggiornandola.
Tra le operazioni sui file troviamo la scrittura, creazione, apertura, cancellazione, riposizionamento ecc…
Le funzioni di apertura di un file richiedono come parametri il nome del file e restituiscono un intero non negativo che è il descrittore del file.
Il SO mantiene delle strutture dati per gestire i file:
- TABELLA GLOBALE DEI FILE APERTI NEL SISTEMA: un vettore che contiene un elemento per ogni file aperto nel sistema.Qui ci sono informazioni come la posizione corrente nel file(se un processo si sposta all’interno del file, questo cambiamento sarà visto da tutti i processi), quanti processi lo stanno utilizzato, protezione ecc…
- TABELLA DEI FILE APERTI PER OGNI PROCESSO: che è un elenco dei file aperti da un certo processo e la sua posizione nella tabella rappresenta il descrittore del file.Questa struttura è all’interno del descrittore del processo.
Ecco le funzioni del linguaggio C per operare sui file…
int creat(char *NomeFile, int Permessi)questa crea un file e restituisce un intero che rappresenta il descrittore del file
int open(char *NomeFile, int Tipo, int Permessi)la open apre un file sulla base del nome passato e ne individua la posizione sul disco.Restituisce sempre un intero che rappresenta il descrittore del file.
- O_RDWR → il file è aperto in lettura e scrittura
- O_WRONLY → file aperto in sola scrittura
- O_RDONLY → file aperto in sola lettura
La lettura e la scrittura richiedono ovviamente che il file sia già stato aperto altrimenti non ho neanche il descrittore che rappresenta la sua posizione nella tabella dei file aperti dal processo.
Il FS mantiene un indicatore alla posizione in cui deve essere effettuata la scrittura successiva.
Esiste anche la possibilità di riposizionare la posizione corrente del file, tramite la funzione lseek,che mi permette di ridefinire la posizione come posizione iniziale(finale o corrente) del file + offset.
long lseek(int fd, long offset, int riferimento)vediamo i valori di riferimento:
- 0: posizione corrente = inizio file+offset
- 1: posizione corrente = posizione corrente precedente + offset
- 2: posizione corrente = fine file + offset
Se ad esempio la invoco con lseek(FD, 0L, 1) la funzione mi restituisce la posizione attuale senza modificarla.
Un’altra funzione interessante è la dup() che consente di duplicare un descrittore di un file già aperto.Crea un nuovo descrittore, non un nuovo file.
Nel fare una fork, abbiamo detto che il figlio condivide la stessa tabella dei file aperti, quindi vengono duplicati i descrittori, che fanno riferimento agli stessi file.Nella tabella globale dei file aperti ovviamente vedrò un nuovo processo che utilizza il file.
Poi c’è la close() che elimina il legame tra descrittore e il file.Non garantisce che i dati scritti in memoria vengano trasferiti direttamente in memoria.Per essere sicuri di questo, devo usare la fsync() prima della close().
Infine ci sono link() e unlink().
int link(char *nome, char *nuovo_nome)questa associa un nuovo nome a un file già esistente e restituisce l’esito operazione.Non viene creato nè un nuovo file nè un descrittore, ma solo un altro nome per individuare il file, un nuovo riferimento.
La unlink sgancia invece un riferimento.Queste sono utili perchè quando non ci sono più riferimenti, si rende libera quella zona di memoria.
Se quando chiudo il file i riferimenti sono zero, allora il descrittore viene rimosso.
C’è la directory iniziale che è la directory root, creata quando si inizializza il SO, mentre le altre vengono create man mano nella configurazione.Da root, che è quindi una directory, cioè un file che contiene nomi di altri file che ha al proprio interno, si creano tutte le altre directory.
Per quanto riguarda i file speciali, cioè le periferiche, nel Filesystem di Linux si trovano sotto il direttorio /root/dev ed è possibile fare delle open, read e write(purchè abbia senso) ma non delle creat(per crearli su usa mknod).
Ogni programma, all’esecuzione, dispone già di 3 descrittori di file: stdin(descrittore 0), stdout(1), stderr(2) associati a tastiera e video.stout e stderr sono il video ma in genere stderr può essere anche usato per scrivere errori.stdin è la tastiera.
Ad esempio, posso chiudere lo standard output cosi: close(1);
Ogni periferica installata è individuata da una coppia di numeri, major e minor.Le periferiche dello stesso tipo hanno stesso major, mentre minor distingue le diverse periferiche all’interno della stessa famiglia.
Il filesystem interagisce con la page cache e c’è una parte che è il gestore del buffer che gestisce i blocchi di file letti da disco.
Il gestore del buffer/cache gestisce la relazione tra blocco di file e sua posizione in memoria centrale indipendentemente dal processo.Quando il FS richiede la lettura di un blocco, passa la richiesta al gestore di buffer e cache.Se nella page cache c’è già quel file viene restituita la posizione in memoria, in caso contrario, il FS deve capire qual’è il blocco logico del VFS che contiene le pagine da allocare, deve chiedere al gestore della memoria di allocare spazio fisico in memoria.A quel punto il gestore del buffer gestisce il trasferimento dei dati e viene trasferito un numero intero di blocchi logici.
Linux crea all’avvio la directory root che poi si dirama in tutte le altre sottocartelle.
diversi volumi, cioè partizioni dotate di un proprio FS, sono rappresentati da nodi dell’albero detti mount_point. Per inserire un nuovo volume è necessario fare due operazioni:
- associare un FS al volume(device)
- montare il volume in un certo mount_point
Siccome devo staccarmi dalle diverse implementazioni del FS, al di sopra di questo c’è il VFS.
Ci sono 3 strutture fondamentali usate dal VFS che sono:
- struct dentry(directory entry): ogni istanza di questa struttura rappresenta una directory nel VFS
- struct inode(index node): ogni istanza rappresenta un singolo file fisicamente esistente nei volumi e contiene i metadati di questo
- struct file:ogni istanza rappresenta un file aperto nel sistema
Nel descrittore del processo, c’è una struct files_struct che serve a identificare i filesystem usati dal processo e quindi tutte le funzioni per operare.struct struct_file è usata nel VFS per rappresentare i file aperti.Il descrittore di un file F è un numero intero che identifica l’elemento all’interno della tabella dei file aperti del processo che si riferisce al file, cioè fd_array[fd] è utilizzato per accedere al file F.
All’interno della struct_file c’è il puntatore alla posizione corrente del file che viene aggiornata dinamicamente, loff_t f_pos.
La dentry punta alla inode.Per accedere a un file ho il descrittore del processo che ha la sua tabella dei file aperti, tramite il descrittore del file trovo la posizione, trovo un puntatore, che va alla struct_file, all’interno della quale trovo il catalogo e poi trovo la inode che mi dice la posizione sul volume.
Quindi se un processo ha un certo file aperto, questo processo avrà una tabella dei file aperti files_struct, che è locale, ma ogni elemento poi fa riferimento alla tabella globale dei file aperti nel sistema.
La tabella dei direttori mi da il percorso per arrivare al file.
f_count poi nella tab glob. dei file dice quanti descrittori puntano a quel file.
Un file è rappresentato nel VFS da un’istanza della struct inode.La corrispondenza tra file e istanze inode è biunivoca.
La lettura di un file è basata però sempre sulla pagina: il SO trasferisce sempre pagine intere di dati ad ogni operazione.Se un processo esegue una system call sys_read anche di pochi byte, il sistema esegue queste operazioni:
- determina la pagina del file alla quale i byte appartengono
- verifica se la pagina è già contenuta nella Page Cache; se lo è passa a →5
- alloca una nuova pagina in Page Cache
- riempie la pagina con la corrispondente porzione del file, caricando i blocchi necessari(4 da 1K per esempio) dal volume
- copia i dati richiesti nello spazio utente all’indirizzo richiesto dalla system call
Per determinare la pagina del file dobbiamo trasformare la posizione corrente nel numero di pagina.
L’operazione 4 richiede la trasformazione del numero di pagina negli LBA dei blocchi che costituiscono la pagina.
Le pagine del file(FP) sono numerate da 0 e indicate con FP0,FP1 ecc…
La trasformazione della posizione corrente, che chiamiamo POS in un FPn può essere realizzata cosi:
il file quindi è strutturato in blocchi.Quindi per FP si divide e si toglie il resto(ad esempio 5000/4096=1).La seconda, % indica il resto della divisione tra POS e 4096.
Il meccanismo generico che avevamo chiamato Page_Cache_Index trattando della Page Cache è realizzato file per file tramite la struttura address_space puntata dal inode di ogni file.
La page cache…
- accede al inode del file
- dal inode accede al page tree, una struttura usata per puntare a tutte le pagine della Page Cache relative a questo file
- carica nel page tree se esiste la pagina FP
Ringrazio i coraggiosi che sono arrivati fino a questo punto dell’articolo 😂
Ho una buona notizia per voi: siamo giunti al termine.
Gli argomenti trattati sono complessi e non a caso infatti vengono trattati nel corso di Architettura dei Calcolatori e Sistemi operativi della facoltà di Ingegneria Informatica.Su questi argomenti è difficile essere brevi data la loro complessità e inoltre nell’articolo sono state fatte anche alcune semplificazioni rispetto a quella che è la realtà.
Oggi il codice del Kernel di Linux è un codice di circa 15 mila righe, potete infatti trovarlo su Github.
L’obbiettivo di questo articolo era quello di diffondere una conoscenza abbastanza avanzata sui sistemi operativi e permettere la lettura anche a chi è semplicemente appassionato di informatica e ha alcune basi di programmazione e un’idea generale di come funziona un computer.
Grazie per la lettura!
Edoardo