
Assemblaggio e Compilazione:Come viene compilato un Codice
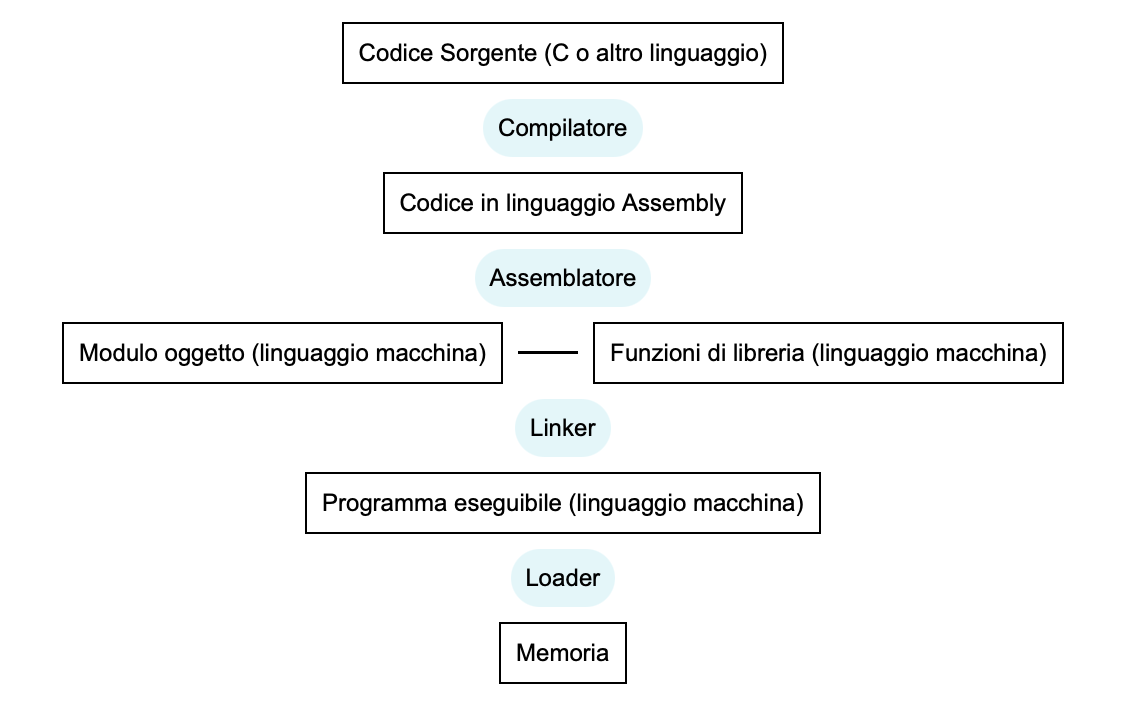
Si vedrà ora come un programma scritto in C, memorizzato quindi in una memoria non volatile, viene, tramite 4 passi(già descritti in precedenza), trasformato in un programma pronto per essere eseguito.
Precisiamo inoltre che l’assemblatore accetta generalmente numeri in base 2,10,8,16.
Il loader è un componente del kernel che legge l’intestazione del file eseguibile per capire di quanto spazio il programma ha bisogno.Il loader carica le istruzioni sulla memoria fisica del computer.
Gli indirizzi si chiamano virtuali non perchè iniziano da 0 ma perchè è il SO che decide quale sarà l’indirizzo fisico in RAM o in memoria permanente(in caso di swapping) che gli corrisponderà.
Gli indirizzi rilocabili sono quelli che sono assegnati in compilazione.
COMPILAZIONE
COMPILATORE:trasforma il programma C in linguaggio Assembler.Il numero di istruzioni di cui è composto un programma in alto livello è molto inferiore rispetto al numero di un programma assembly. Le pseudoistruzioni, non sono implementate dall’hardware ma che l’assemblatore capisce ed espande in istruzioni comprese dall’hardware.Ad esempio è cosi che si espande una li:
li x9, 100 #pseudoistruzioneaddi x9,x0,100 #traduzioneLa comodità delle pseudoistruzioni è appunto avere più istruzioni di quelle predisposte dall’hardware.
ASSEMBLAGGIO
Il codice sorgente viene inizialmente normalizzato,prima della traduzione e qui tutto ciò che è dichiarato con .eqv viene sostituito.Ecco le fasi:
- traduzione delle pseudoistruzioni in istruzioni RISC V(vengono espanse)
- definizione degli indirizzi corrispondenti a tutte le etichette e inserimento nella tabella dei simboli (una riga per ciascun simbolo a cui corrisponde un indirizzo)
– alla fine dell’analisi del file corrente, possono rimanere dei riferimenti non risolti (che sperabilmente saranno definiti in un altro file)
- generazione del file oggetto
OBJECT FILE HEADER TEXT SEGMENT DATA SEGMENT SYMBOL TABLE DEBUGGING INFO
Assemblatore – Traduzione delle etichette
.text # segmento testo (codice)
.globl MAIN # simbolo globale
MAIN: addi sp, sp, -64
sd ra, 24(sp)
sd a0, 48(sp)
sd zero, 32(sp)
sd zero, 40(sp)LOOP: ld t6, 40(sp)
sub t3, t6, t5
ld t6, 32(sp)
add t6, t5, t4
sd t6, 32(sp)
addi t0, t6, 1
sd t0, 24(sp)
li t1, 100
ble t0, t1, LOOP
la a2, STR
ld a3, 32(sp)
jal PRINTF
move a0, zero
ld ra, 24(sp)
addi sp, sp, 64
ret
.data # segmento dati
.align 0 # allinea a byteSTR: .asciz "Sum of 1..100 is %d\n"- Etichetta locale: LOOP e STR, visibili solo in questo file (modulo)
- Etichetta globale (esterna): MAIN, visibile all'esterno
- Riferimento non risolto: PRINTF (procedura di libreria per stampare a terminale)
Nota: L’etichetta STR viene utilizzata (citata) prima di essere definita.
L'assemblatore lavora in due passi:
- Individua tutte le etichette e le inserisce nella tabella dei simboli
- Traduce le istruzioni assembler in linguaggio macchina utilizzando le informazioni nella tabella dei simboli e considerando che il programma inizia all'indirizzo 0 producendo la tabella di rilocazione del modulo in esame
Attenzione: Questo codice è il risultato di compilazione con gcc con l’opzione di security riguardante la stack protection non disabilitata!
Questo è il motivo per cui sembra non rispettare le regole che ci siamo detti...
Qui l’importante è focalizzarsi sull’uso delle etichette!
PRINTF è un simbolo non risolto cioè a quel simbolo deve essere associato un valore, che non può essere assegnato dall’assemblatore ma dal linker.
C’è una opzione che permette di disabilitare la stack protection.Ce ne sono altre che bloccano il caricamento in memoria(SLR,…).
Per produrre la versione binaria di ogni istruzione di un programma,l’assembler deve determinare tutti gli indirizzi corrispondenti a ciascuna etichetta.Un file oggetto contiene:
- intestazione del file oggetto(object file header):descrive la dimensione e la posizione degli altri segmenti del file oggetto stesso
- segmento testo(text segment):codice in linguaggio macchina
- Segmento dati statici(static data segment):contiene tutti i dati allocati per tutta la durata del programma
- informazioni di rilocazione(relocation information):identificano le istruzioni e i dati che, quando il programma è posto in memoria, dipendono da indirizzi assoluti
- la tabella dei simboli(symbol table):contiene le rimanenti etichette di cui non è stata trovata una definizione, per esempio quelle che fanno riferimento ai moduli esterni
- Le informazioni per il debugger:contengono una descrizione concisa di come sono stati compilati i moduli, in modo che il debugger possa associare le istruzioni in linguaggio macchina al codice sorgente C e rendere leggibili le strutture dati
Nel primo passo l’assemblatore non traduce nessuna istruzione ma costruiscela tabella dei simboli del modulo.I riferimenti simbolici inseriti nella tabella possono essere
- etichette che definiscono variabili del segmento dati – nella tabella si crea
la coppia <simbolo, indirizzo>
- etichette che contrassegnano istruzioni destinazioni di salto – nella tabella
si crea la coppia <simbolo, indirizzo>
I valori degli indirizzi inseriti sono quelli rilocabili ( cioè usati nel momento in cui
agisce il
collegatore) rispetto al segmento considerato (segmento testo T o
segmento dati D)
La seconda è la fase di traduzione vera e propria: usa la tabella dei simboli del modulo e genera
– oltre alla traduzione – la tabella di rilocazione del modulo un’istruzione è tradotta in modo «incompleto», e deve quindi essere elaborata anche da parte del collegatore (linker), se:
- il riferimento simbolico presente in essa è relativo a variabili del segmento .data;
p.es. la pseudoistruzione la viene espansa tramite auipc e addi con
immediati convenzionali a
0, che andranno poi calcolati da collegatore
- il riferimento è relativo a simboli non (ancora) presenti nella tabella dei simboli
del modulo: il simbolo viene posto a
0 per convenzione e andrà poi calcolato
- il riferimento simbolico presente in essa è relativo a simboli su cui agisce un
modificatore;
p.es. la pseudostruzione li con il valore espresso tramite
un’etichetta, viene espansa tramite
lui e addi con immediati convenzionali
a
0, che andranno poi calcolati
L'assemblatore non è coinvolto in questo processo di traduzione degli indirizzi virtuali in indirizzi fisici. Il suo compito principale è convertire il codice assembly in istruzioni binarie per l'esecuzione sulla CPU. La gestione degli indirizzi virtuali e fisici è una funzione separata eseguita dal sistema operativo e dall'hardware.
L'assemblatore e il linker svolgono ruoli diversi nella creazione del file eseguibile e nella gestione dei simboli e delle tabelle di rilocazione. Ecco come funziona il processo:
- Assemblatore: L'assemblatore è responsabile della traduzione del codice assembly in istruzioni binarie (linguaggio macchina) e della creazione di un file oggetto. Durante questo processo, l'assemblatore genera anche una "tabella dei simboli", che contiene informazioni sui simboli definiti e utilizzati nel codice. Questi simboli possono essere etichette di variabili, funzioni o puntatori a simboli esterni.
- Linker: Il linker è responsabile della fase di collegamento, che coinvolge la combinazione di uno o più file oggetto (compilati separatamente) in un file eseguibile completo. Durante questa fase, il linker utilizza la tabella dei simboli generata dagli assembler per risolvere riferimenti simbolici tra i vari file oggetto. Questo può includere la risoluzione di riferimenti a funzioni o variabili definite in un file oggetto ma utilizzate in un altro. Il linker crea quindi una "tabella di rilocazione" che indica come adattare gli indirizzi relativi nei vari file oggetto per ottenere gli indirizzi corretti nell'eseguibile finale.
- Tabelle di Rilocazione: La tabella di rilocazione contiene informazioni su come adattare gli indirizzi relativi nei vari file oggetto per ottenere gli indirizzi fisici effettivi nell'eseguibile finale. Questo può includere l'aggiunta di offset o correzioni per garantire che gli indirizzi siano coerenti con l'ambiente di esecuzione effettivo.
Quando il programma viene eseguito, il sistema operativo si occupa di tradurre gli indirizzi virtuali dell'eseguibile finale in indirizzi fisici durante la fase di caricamento in memoria. Questo processo di traduzione degli indirizzi virtuali in indirizzi fisici è gestito dal sistema operativo utilizzando strutture di gestione della memoria come la tabella delle pagine, come descritto in precedenza.
In breve, l'assemblatore crea la tabella dei simboli, il linker crea la tabella di rilocazione, ma la traduzione effettiva degli indirizzi virtuali in indirizzi fisici è gestita dal sistema operativo durante l'esecuzione del programma.
LINKER
La modifica,anche di una sola linea di codice richiederebbe, senza linker l’intera ricompilazione e riassemblaggio di tutto il programma,un vero spreco di risorse computazionali.Allora, per ovviare a ciò, si compila ciascuna procedura in modo indipendente dalle altre, in modo che la modifica di una linea di codice, rende necessaria soltanto la ricompilazione e riassemblaggio della sola procedura in cui l’istruzione era.
Esso esegue i seguenti 3 passi:
- inserisce in memoria in modo simbolico il codice e i moduli dati
- determina gli indirizzi dei dati e delle etichette che compaiono nelle istruzioni
- corregge i riferimenti interni ed esterni
Il linker utilizza le informazioni di rilocazione e la tabella dei simboli di ciascun modulo oggetto per risolvere tutte le etichette non definite. Queste si trovano nelle istruzioni di salto e negli indirizzi dei dati; il compito del linker è quindi più o meno quello di un editor: trovare gli indirizzi vecchi e sostituirli con quelli nuovi. Questa attività di editing è all'origine del nome link editor, abbreviato in linker.
Dopo che tutti i riferimenti esterni sono stati risolti, il linker determina le locazioni di memoria che ciascun modulo dovrà occupare. Poiché tutti i file vengono assemblati in modo indipen-dente, l'assemblatore non può conoscere la posizione relativa delle istruzioni e dei dati di un modulo rispetto a un altro; perciò, quando il linker inserisce un modulo in memoria, tutti i riferimenti assoluti, cioè gli indirizzi di memoria definiti non in relazione a un registro, devono essere rilocati in modo da poter riflettere la loro reale posizione. Il linker produce un file eseguibile che può essere eseguito su un calcolatore. Di norma questo file ha lo stesso formato di un file oggetto, ma non contiene più riferimenti non risolti. E’ possibile eseguire questo passo anche in maniera parziale, come è il caso delle librerie, che contengono ancora indirizzi non risolti e quindi in realtà sono assimilabili a file oggetto.
Quindi il linker utilizza la tabella dei simboli creata in assemblaggio e la fa diventare tabella di rilocazione.Attenzione:nella tabella di rilocazione non ci sono gli indirizzi virtuali, questi verranno generati dal SO al momento dell’esecuzione e si occuperà della loro traduzione in indirizzi fisici durante l’esecuzione.
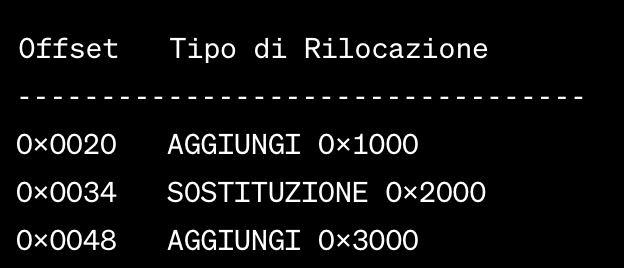
ecco cosa c’è nelle tabelle di rilocazione:
- Offset: L'offset rappresenta l'indirizzo relativo all'istruzione o al dato nel file oggetto. Questo valore indica quanto l'indirizzo deve essere modificato per ottenere l'indirizzo assoluto o fisico corretto. L'offset può essere espresso in varie unità, come byte o parole di istruzioni, a seconda dell'architettura e del formato del file oggetto.
- Tipo di Rilocazione: Il tipo di rilocazione specifica il tipo di correzione da applicare all'offset per ottenere l'indirizzo fisico corretto. Ad esempio, può indicare se è necessario aggiungere un certo valore all'offset o se è necessario sostituire un valore con un altro.
Ecco un esempio semplificato di come potrebbe apparire una tabella di rilocazione in un file oggetto (usando un formato immaginario per scopi illustrativi):
in corrispondenza di ogni traduzione incompleta viene creato un elemento nella tabella
di rilocazione, nella forma
< indirizzo rilocabile istruzione, codice op. istruzione, simbolo da risolvere (con modificatore)>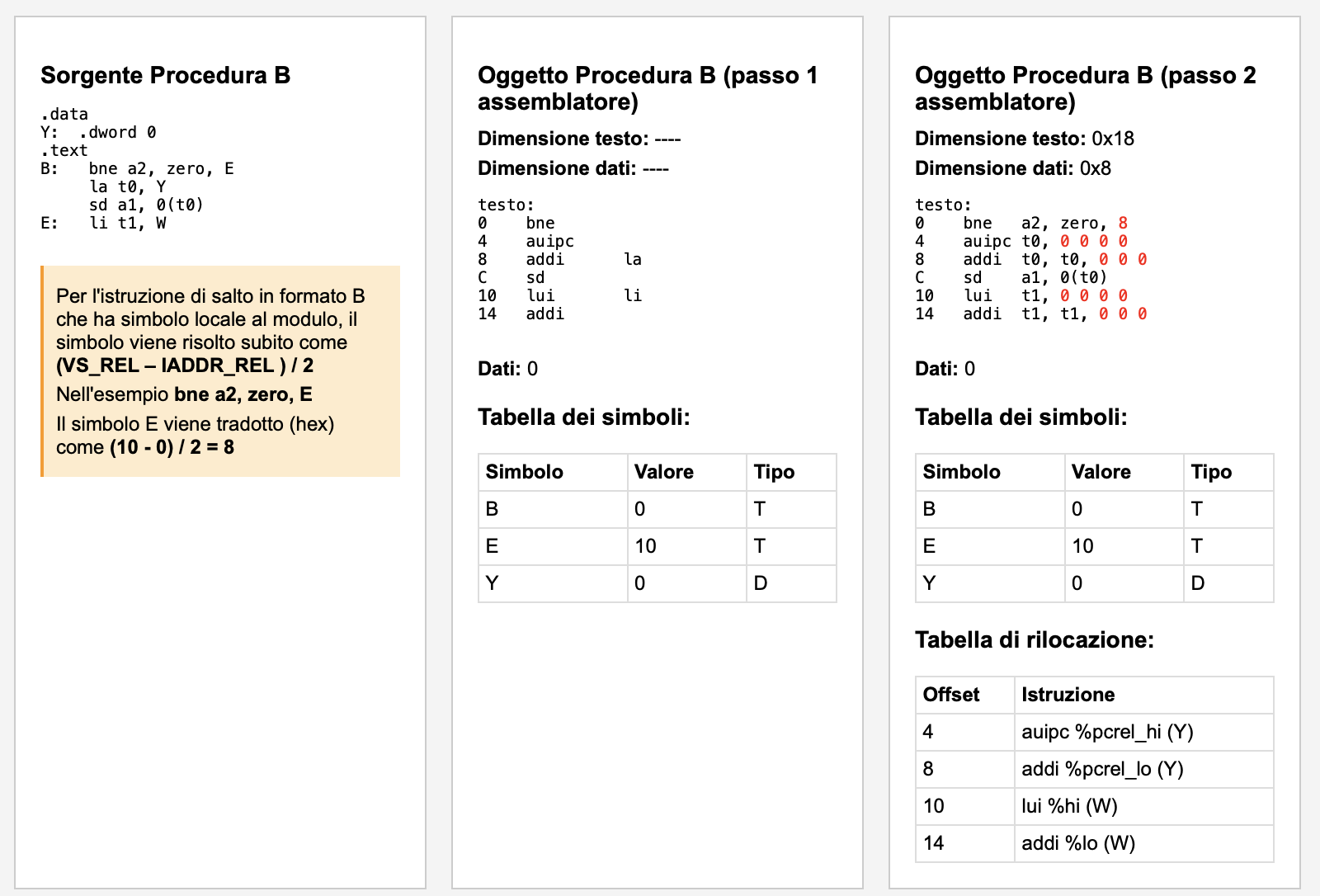
Ciò che verrà aggiunto al PC è riportato nella vormula (VS_REL-IADDR_REL)/2.
in fase di collegamento gli indirizzi definiti all’interno di un modulo possono cambiare se la base dello spazio di indirizzamento virtuale del modulo viene modificata (rilocazione del modulo) pertanto, tutte le etichette che corrispondono a indirizzi assoluti all’interno del modulo (in pratica tutte eccetto quelle delle direttive.eqv), costituiscono simboli il cui valore può cambiare al momento del collegamento un simbolo usato in un’istruzione di un modulo è locale se è definito nello stesso modulo, esterno in caso contrario l’assemblatore non traduce completamente le istruzioni nelle quali si fa riferimento a:
• un simbolo esterno al file in esame, perché non ne conosce il valore
• un simbolo rilocabile (interno o esterno al file in esame), perché il valore del simbolo cambierà in fase di collegamento, ma con l’eccezione seguente:
– le istruzioni di salto che fanno riferimento a simboli locali che vengono
relativizzati rispetto al PC possono essere tradotte completamente, perché la distanza dal PC non cambia quando il modulo viene rilocato (si dice che sono
autorilocanti)

Ad esempio se usando gcc scrivo un’istruzione del tipo:
gcc NOMEFILE_1 NOMEFILE_2il compilatore saprà che dovrà creare un eseguibile partendo da quei 2 file.
Nell’esempio di sopra è riportato ciò che fa l’assemblatore.
Operazioni svolte dal LINKER
- Determimna la posizione in memoria, nello spazio di indirizzamento virtuale del nostro programma. Individua quindi indirizzo iniziale, o di base e delle varie sezioni(codice,dati, moduli ecc…).
- determina il nuovo valore di tutti gli indirizzi simbolici che risultano modificati dallo spostamento della base e crea la tabella globale dei simboli
- corregge nei moduli i riferimenti a indirizzi simbolici che sono cambiati, dalla tabella di rilocazione
Ovviamente perchè ciò sia possibile, oltre al codice, i moduli oggetto devono contenere altre informazioni(viste nella tabella di prima, che riporto qui sotto):
| OBJECT FILE HEADER | TEXT SEGMENT | DATA SEGMENT | SYMBOL TABLE | DEBUGGING INFO |
C’è una dimensione massima dello stack ovviamente.
LOADER
Una volta che il file eseguibile è stato memorizzato su disco, il sistema operativo può leggerlo e trasferirlo in memoria per avviarne l'esecuzione. Nei sistemi UNIX il loader (programma di caricamento) esegue i seguenti passi.
- Lettura dell'intestazione del file eseguibile per determinare la lunghezza del segmento testo e del segmento dati.
- Creazione di uno spazio di indirizzamento sufficiente a contenere testo e dati.
- Copia delle istruzioni e dei dati dal file eseguibile in memoria.
- Copia nello stack degli eventuali parametri passati al programma principale.
- Inizializzazione dei registri del calcolatore e impostazione dello stack poin-
ter affinché punti alla prima locazione libera.
- Salto a una procedura di start-up (avviamento), la quale copia i parametri nei registri argomento e chiama la procedura principale del program-ma. Quando la procedura principale restituisce il controllo, la procedura di startup termina il programma con una chiamata alla funzione di sistema exit.
Approfondimento:Librerie Dinamiche
Abbiamo illustrato il metodo tradizionale, noto come collegamento statico, che prevede il caricamento delle librerie prima dell'esecuzione del programma. Sebbene questo metodo permetta un accesso rapido alle funzioni di libreria, presenta alcuni limiti:
- Le funzioni della libreria diventano parte integrante del file eseguibile. Se una libreria viene aggiornata, ad esempio per correggere bug o aggiungere supporto a nuovo hardware, i programmi che usano il collegamento statico continueranno a utilizzare la vecchia versione.
- Tutte le funzioni della libreria vengono caricate, indipendentemente da quando o se effettivamente utilizzate durante l'esecuzione. Ciò può risultare inefficiente, dato che le librerie, come nel caso della libreria standard C su un sistema RISC-V con Linux, possono essere molto più voluminose del programma stesso (ad esempio, 1,5 MiB).
Queste limitazioni hanno portato alla creazione delle librerie a caricamento dinamico (DLL, Dynamically Linked Libraries), che vengono collegate e caricate solo al momento dell'esecuzione del programma.